Layman’s Introduction to Backpropagation

Training a neural network is no easy feat but it can be simple to understand it
Backpropagation is the process of tuning a neural network’s weights to better the prediction accuracy. There are two directions in which information flows in a neural network.
- Forward propagation — also called inference — is when data goes into the neural network and out pops a prediction.
- Backpropagation — the process of adjusting the weights by looking at the difference between prediction and the actual result.
Backpropagation is done before a neural network is ready to be deployed in the field. One uses the training data, which already has known results, to perform backpropagation. Once we are confident that the network is sufficiently trained we start the inference process.
These days backpropagation is a matter of using a single command from a myriad of tools. Since, these tools readily train a neural net most people tend to skip understanding the intuition behind backpropagation. Understandably so, when the mathematics looks like this.

But it makes a lot of sense to get an intuition behind the process that is at the core of so much machine intelligence.
The role weights play in a neural network
Before trying to understand backpropagation let’s see how weights actually impact the output i.e. the prediction. The signal input at the first layer of propagates ahead into the network through weights that control the connection strength between neurons of adjacent layers.
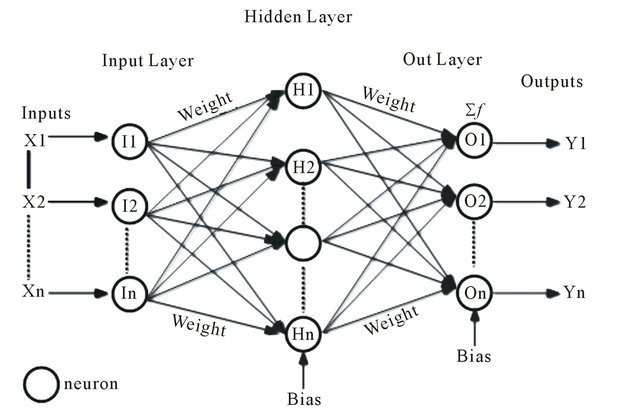
Training a network means fine tuning its weights to increase the prediction accuracy
Tuning the weights
At the outset the weights of a neural network are random and hence the predictions are all wrong. So how do we change the weights such that when shown a cat the neural network predicts it as a cat with a high confidence?
- One Weight At a Time: One very rudimentary way to train a network could be to change one weight keeping others fixed at a time.
- Weight Combinations: Another approach could be to set all weights randomly within a range (let’s say from 1 to 1000). One could start with all 1’s and then all 1’s and one 2 and so on. The combinations would look like this — (1,1,1), (1,1,2), (1,2,1), (1,2,2), (2,2,2), (2,2,3)
Why both of these approaches are bad?
They are because theyIf we are to try all possible combinations of N weights, each ranging from 1 to 1000 only, it would take a humongous amount of time to sift through the solution space. For a processor running at 1GHz a 2 neuron netowork would take 1⁰⁶/1⁰⁹ = 1 millisecond. For a 4 neuron network the corresponding processing time would be 16 minutes and would keep on increasing exponentially for bigger networks.
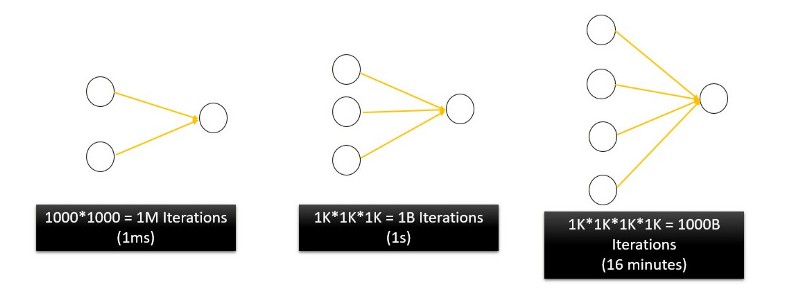
For 5 neuron network that would be 11.5 days. That’s the curse of dimensionality. A real neural network will have 1000s of weights and would take centuries to complete.
This is where backpropagation comes to the rescue
The mathematics is easy to understand once you have an intuitive idea of what goes on in backpropagation. Let’s say a company has 2 sales person, 3 managers and 1 CEO. Backpropagation is CEO giving feedback to middle management and them in turn doing the same to sales people.
Each layer employee reports to all the succeeding layer managers with varying ‘strengths’ indicated by the width of the arrow. So a few employees report more regularly to one manager than others. Also the CEO considers the inputs of Design Manager (bottom neuron in the 2nd layer) more seriously than the inputs of the Sales Manager (bike rider).
Everytime a sale is made the CEO computes the difference between the predicted result and the expected result. The CEO readjusts slightly how much ‘weight’ does he want to place on which manager’s words. The manager reporting structure in turn changes in accordance to the CEO’s guidelines. Each manager tries to readjusts the weights in a way that keep him/her better informed.
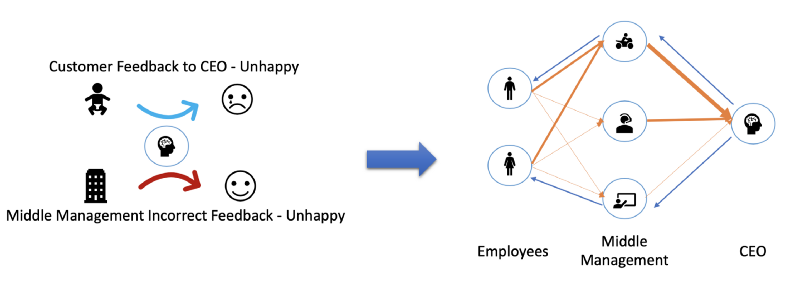
CEO readjusts his trust on the middle management.
This propagation of feedback back into the previous layers is the reason it is called backpropagation.
CEO keeps changing his levels of trust until the Customer Feedback starts matching the expected results.
Slight bit of Maths

A pinch of mathematics
The success of a neural network is measured by the cost function. Less the cost better has it been trained. The goal is to modify weights in such a way so as to minimize the cost function.
So two important terms —
- Error = Difference between Expectation and Reality
- Gradient Of Cost Function = The change in cost upon changing weights.
The aim is to compute how much each weight in the preceding layer needs to be changed to bring expectation closer to reality i.e. bringing the error close to 0
Backpropagation contains the word ‘back’ in it. What that means is that we go from output back towards the input. We look at how error propagates backward.
Look how δˡ depends on δˡ⁺¹
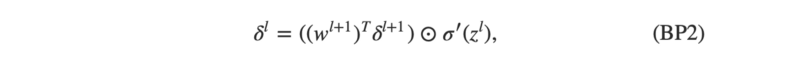
If you look closely there is a z in the second term of the equation. We are measuring there the speed with which z changes. That tells us how fast the error would change because δˡ also depends on z = the output of a neuron.
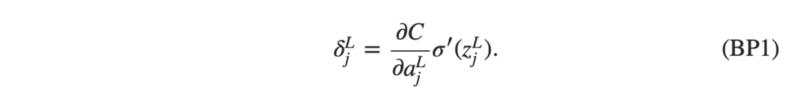
The first term on the right, just measures how fast the cost is changing as a function of the jth output activation. The second term on the right, measures how fast the activation function σ is changing at the output of jth neuron.
Results flow forward, error flows backward. Since we backpropagate the error we need a numerical representation of how error flows between two adjacent layers. Rate of Change of cost with respect to weights is given by
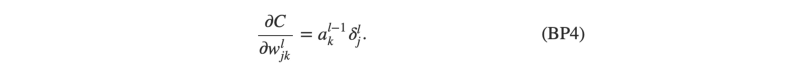
With these basics in place the backpropagation algorithm can be summarized as follows

Practical considerations from a machine learning perspective
- Even backpropagation takes time. It’s better to divide input data into batches. (Stochastic Gradient Descent).
- The more the training data, the better the weight tuning. Generally neural nets requires thousands of pre-labelled training examples.
Backpropagation, though popular now, faced its share of opposition when it was introduced. A lot of prominent scientists and cognitive psychologists (including the famous British cognitive psychologist Geoff Hinton) have been known to distrust backpropagation. Backpropagation faces opposition on account of a lot of reasons including it not being representative of how brain learns.
Nevertheless it is still a very widely used and a very efficient method for training neural networks. Specialized hardware is being developed these days to perform backpropagation even more efficiently.
 Dom Galeon
Dom Galeon
Member discussion