Getting Started With Regular Expressions for NLP

Every now and then a data scientist comes across a text processing problem. Whether it is searching for titles in names or dates of birth in a dataset, regular expressions rear their ugly head very frequently. A regular expression is enough to scare any programmer beyond wits.

Building a regular expression takes some skill. However, decoding a regular expression that has been written by someone else is a nightmare. Luckily, the best way to learn to decipher regular expressions is to understand how to build them from scratch.

A regular expression is a sequence of characters that defines a search pattern. They are used to match character combinations in strings. A very common example of a real world use is when websites verify whether the email address you entered is valid or not.
Our end goal will be to identify the various portions of an email address.

But before we do that let us see how to build a regular expression. We will use a sample text. It is a subset of the description of New York Times that appears in Wikipedia.
The New York Times (sometimes abbreviated as the NYT and NYTimes) is an American newspaper based in New York City[5][6][7] Founded in 1851, the paper has won 130 Pulitzer Prizes, more than any other newspaper.[8][9] The Times is ranked 18th in the world by circulation and 3rd in the U.S.[10] Nicknamed "The Gray Lady",One can easily perform regex-matching online.
List of regex operations
We will explore searching for the following
- Individual characters
- Range of characters
- Negation of a set of characters
- Long string combinations
- Special characters
? * + . - Anchors (Beginning and end of line)
- Escaping special characters
1. Matching individual characters — [wW]
When any character(s) is placed inside square brackets, all occurrences of it are matched. Let’s match all capital N’s in the text above. We do that by using the regular express [N]
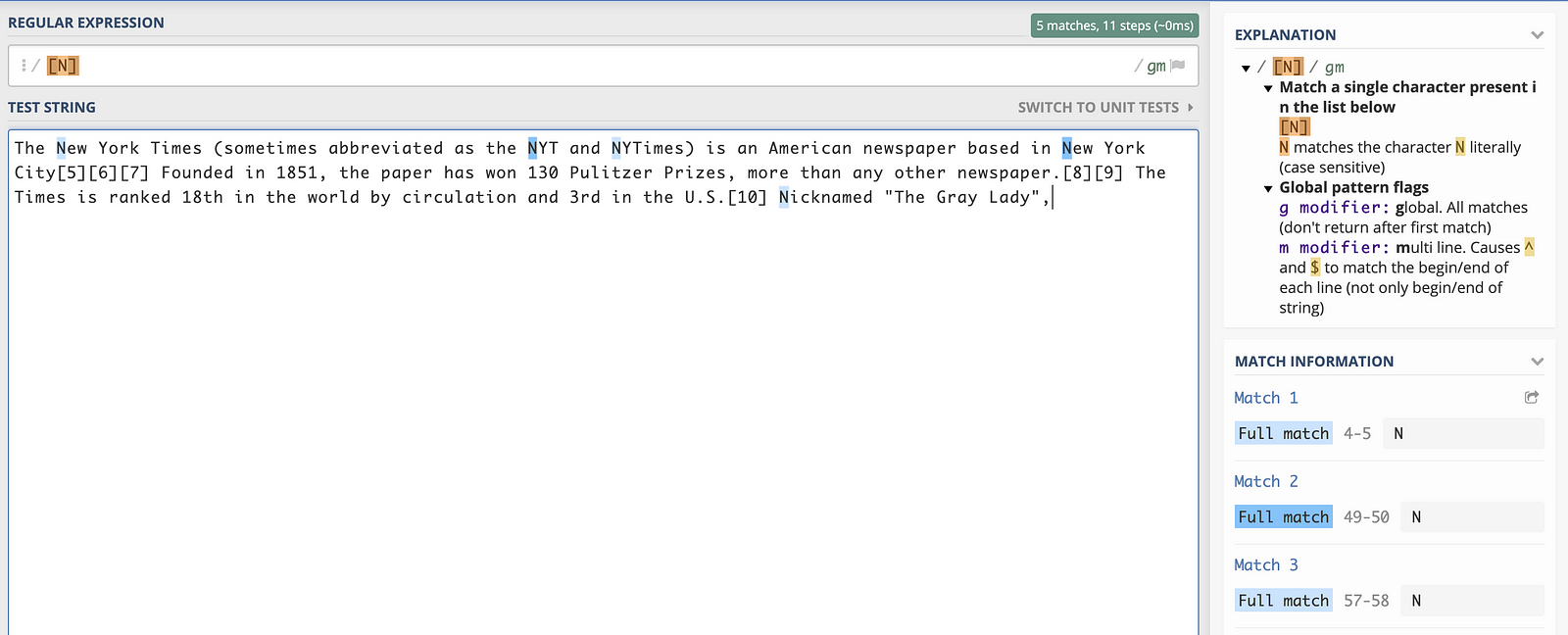
If we wanted to match all N’s whether small or capital we would do [Nn]

To match all the whitespaces we do [ ]

2. Matching a range of characters or numbers — [A-Z]
To match all capital letters we will use the regular expression [A-Z] .

To match all the numbers in the text we will do [0-9] .

All lower case letters can be matched by using [a-z]

3. Negation— [^]
A carat ^ when placed inside a pair of square brackets and at the very beginning matches the opposite of what follows. For example to match all characters other than A — Z, a — z and 0–9, we do [^A-Za-z0-9]

Note that this matches brackets, commas and spaces. Let’s remove spaces from the match list. [^A-Za-z0-9 ]

4. Pipe Symbol — this|that
Pipe symbol | is used when there is a need to match with long strings, otherwise it is similar to [] .
a|b|c is the same as [abc]Let’s try matching New and York both — New|York

Adding more words to the search list

5. Special Characters — ? * + .
These special characters match to zero or more occurrences of the character occurring prior to them. Let’s see an example of each
?— The previous character is matched optionally. That means it is matched 0 or 1 time. Let’s say we want to match all thetheandotherin the text. So we will keep theoand therinotheroptional.o?ther?

Note: This matches both the 'the' and the 'other' in the text.Another simplified text illustrates this better. Note only 2 words are matched below when we use the ? in wha?t

What if we wanted to match the other words as well? We would use a *
*— matches 0 or more occurrences of the character before it.

Note that there are 5 matches. Even wht is matched as * matches 0 or more occurrences
+on the other hand matches 1 or more occurrences

Note: 'wht' is not matched.matches any 1 character.

6. Anchors — ^ $
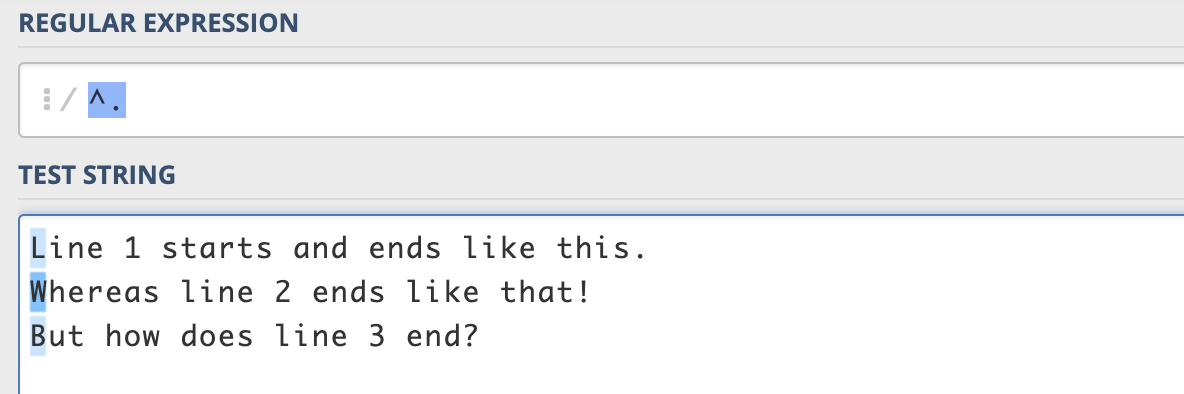
Anchors match at the ends of the line. ^ matches beginning, $ matches the end. Remember the carat acts like a negation only inside square brackets outside of them it matches beginning of sentences.
^.matches 1 character at the beginning of the sentence
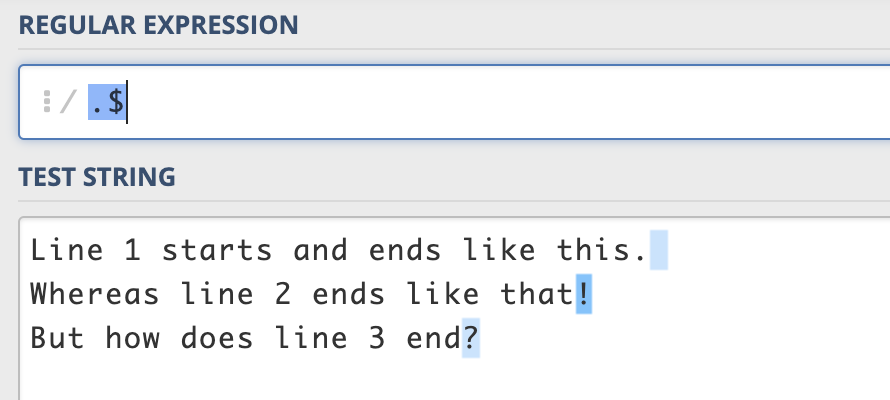
.$matches 1 character at the end of the line
7. Escaping Special Characters — \
Finally, if special character match other characters, how do we search for special characters themselves in a text. Let’s say our text is the following
* is a star , while . is a dot and say what you may we add using + and often end our questions in a ?\*— is used to escape the star\.— is used to escape the dot\+— is used to escape the plus sign\?— is used to escape the question mark
And we club them together using the pipe symbol | .
\*|\.|\+|\? is used

Email Validation
Now let’s try to identify the various parts of an email using python regex.
Username
We will need to extract all alphabets and numbers and dots before the @ sign. The following regexes will get us what we want
- A single alphabet or a number —
[A-Za-z0-9] - Multiple “alphabets and numbers” —
[A-Za-z0-9]* - Anything before an @ sign —
()@
Combining these 3 we get ([A-Za-z0-9\.]*)@
Domain
We will need to extract all alphabets and numbers after the @ and before the first dot. The following regexes will get us what we want
- Anything after the @ —
@() - Anything before a dot —
()\. - Multiple “alphabets and numbers” —
[A-Za-z0-9]*
Combining these 3 we get @([A-Za-z0–9]*)\.
TLD
We will need to extract all alphabets after the dot that occurs after the domain name. The following regexes will get us what we want
- Anything after the domain name—
regex-for-domain-name()=@[A-Za-z0–9]*\. - Multiple “alphabets and numbers” —
[A-Za-z0-9]*
Combining these 2we get @[A-Za-z0–9]*\.([A-Za-z\.]*)
Testing with Python
Now let’s test a few email addresses with the following python code.
The output
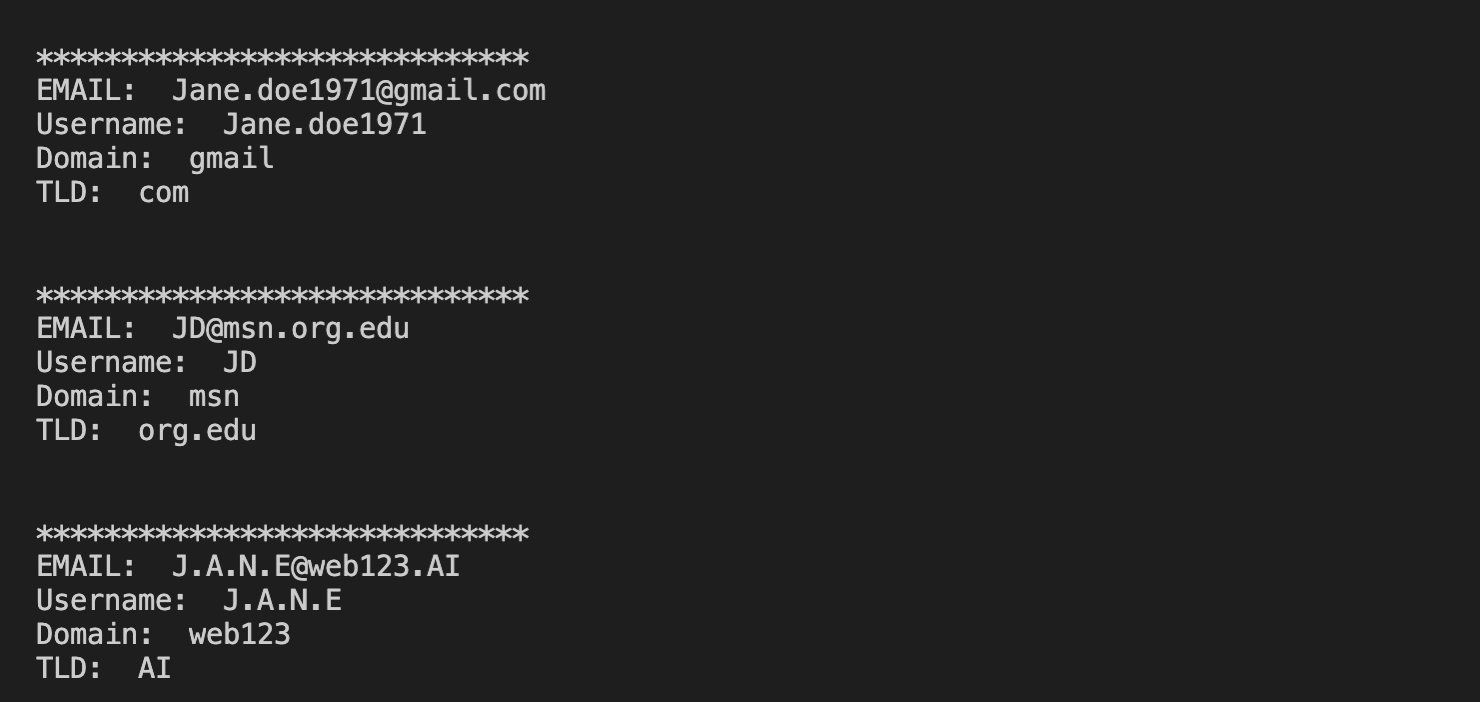
Look at how the various different email IDs are processed.
Regular expressions play a surprisingly important role in Natural Language Processing (NLP). Sophisticated expressions are often the first model for any text processing task. Even though complex NLP tasks involve machine learning classifiers, quite often, regular expressions are used as features for these classifiers.
For more information on NLP and other machine learning concepts head-over to our Machine Learning section
Member discussion