Recommendation Systems
Data speaks louder than words
How many times have you clicked on an item that Amazon suggested and bought it? How many times have you viewed a movie or heard a song suggested by Netflix or Spotify and liked it? Have you ever wondered how do these websites know what you might like?

The answer lies in Recommendation Systems. These systems take in the inputs of your likes, dislikes, preferences, past history, purchases and much more, to generate insights about what you would like in future. Think of them as a computer’s way of reading your mind.
The Concept of Recommendation Systems
To understand the fundamentals of Recommendation System, let us use a simple toy example.
In the good old days when there was no concept of e-commerce, we come across a group of three movie lover friends — Alpha, Beta and Gamma. Alpha and Beta went to watch a movie (Back to the Future), but they come back with different reviews. Alpha loved it but Beta found it intolerable. Over dinner, Alpha recommends Gamma to watch the movie whereas Beta recommends otherwise. Gamma is confused! She doesn’t want to waste her time watching a bad movie, but at the same time she doesn’t want to miss out on a movie she might like.
How can she make this decision without watching the movie?
She decides to recall her past history and experiences with her friends to figure out the common likes and dislikes between herself and her friends. She comes up with this table:

Based on the table of historical data, Gamma does the following calculation to find similarity (correlation) of choices between her friends and herself and finds out that she is more similar to Alpha in her tastes.
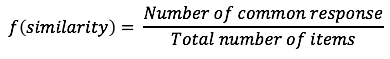

Hence, the chances of her liking the movie (i.e., Alpha’s recommendation) is 50%, while the chances of her not liking the movie is 25% (i.e., Beta’s recommendation). Based on this simple ‘recommendation system’, she decides to watch the movie.
Different Kinds of Recommender Systems
Apart from the basic technique used by Gamma in the example above there are a multitude of different algorithms used by recommender websites. In the previous example Gamma was limited by data (number of friends, number of common movies they have watched).
However in the today’s world, there is so much data, that you don’t need friends for personal recommendations. The Recommendation Engines deployed by the e-commerce websites will do the hard work of finding friends (similar users will like similar items) for their users amongst the millions visiting their pages. These engines then use the discovered friendships to help their users explore wider range of items that they might not have even heard of.
A few flavors of such systems available in the market include the following (see this link for an overview of different kinds of recommender systems):
- Memory Based Collaborative filtering (focus of this article): Using the interactions of users and products for generating recommendations.
- Content Based filtering: Using the information about the product to recommend them to the users
- Using deep learning to build recommendation system
Memory Based Collaborative Filtering
Why is it called Memory Based? Because it needs all the history of ratings (likes/dislikes) about the user of interest in working memory to compute similarities.
Why is it called Collaborative Filtering? Because it filters (i.e., gives predictions) down to the items of interest using the large database of multiple users’ rating (collaborative).
There are two forms of Memory Based collaborative filtering (User Based and Item Based) and both of them rely on the history of ratings given by different users. For both of these methods, we will use the data of user’s ratings for items shown in Table 1. We have data of 5 users (rows of the table) who have reviewed a few items (columns of the table) each among the 9 items that we have in our database.
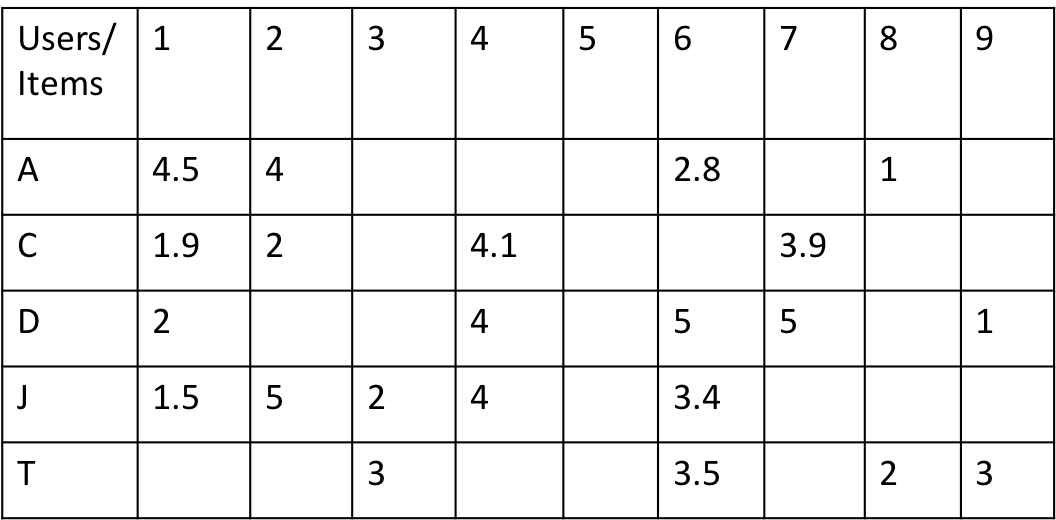
1. User based collaborative filtering (user-item)
The first algorithm we will learn is called User based collaborative filtering which is a two step process.
Step 1
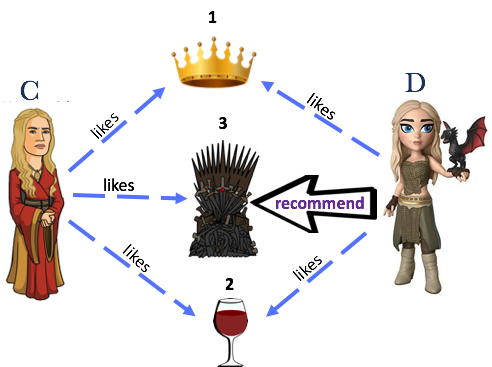
Find the users similar to the current user i.e. the one with the highest similarity score, as shown in the image below. (We will discuss how to generate similarity scores later, for now let’s assume that we know the similarity scores). Based on the scores we find that current user D is closest to the user C in our existing database.
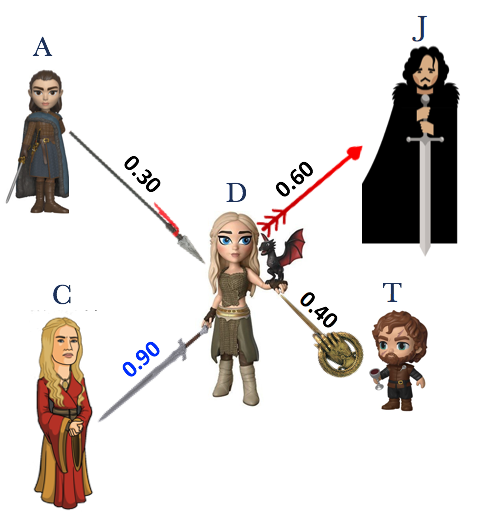
Step 2
Recommend the items to the current user (D) that the other similar users (currently we will consider only the most similar user C) like. In the image below we find that C liked Item 3, but D hasn’t purchased it yet, so we recommend it to D.
Coming back to the question of finding similarity scores between users.
Recall that in our earlier example of three friends, Gamma figured out that she is more similar to Alpha using the following similarity function:
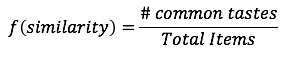
This worked for her because there were only two responses possible (like or dislike). But what happens in a scenario (as shown in the Table 1) when users assign ratings to the items, say, between 1 to 5?
In this case, we can define another similarity function that can handle this scenario. For the purposes of this article we will use the inverse Euclidean distance as our similarity function (shown below).
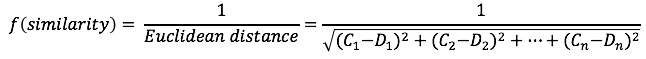
Let’s walk through a simple example to calculate the similarity score between user C and user D, in the Table 1.
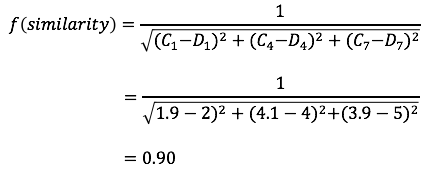
Now we extend this calculation of similarity score to all users in our database to generate the table below.
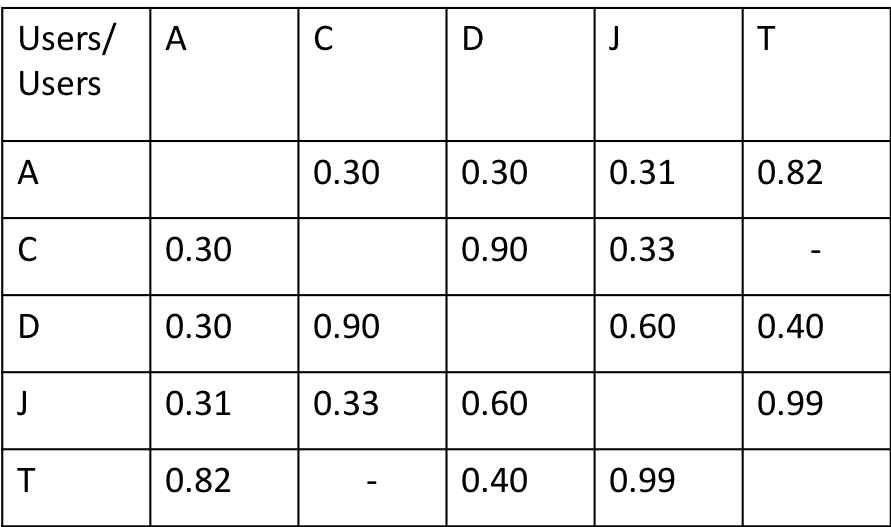
The similarity score - means that these 2 users have never reviewed anything common (refer to Table 1).
Based on the Similarity Table for Users we know that the D is very similar to C. So we should recommend other items rated high by C to D, followed by highly rated items from J, T and A.
Also note that for A the most similar user is T, whereas for T the most similar user is J, hence even though similarity score is commutative, the most similar user is not a commutative function.
2. Item based collaborative filtering (item-item)
In the previous algorithm (user based) we focused on finding similar users. On the other hand Item based filtering approaches the problem from the perspective of similar items.
When a user purchases an Item I, we recommend other items similar to the Item I to the user.

Analogous to user based collaborative filtering, now we will find similarity between items. Since we considered user pairs for calculating similarities between the users in the database, in this case we will consider the item pairs to determine the similarities between the items.
To find similarity between Item 1 and Item 2 , we need to find inverse of Euclidean distance between Column 1 and Column 2 of Table 1.
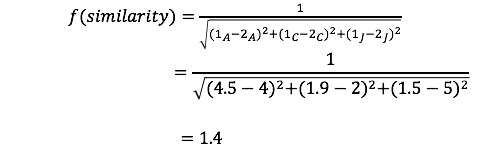
Let’s extend this calculation of similarity score to all the items in our database to generate the table below.
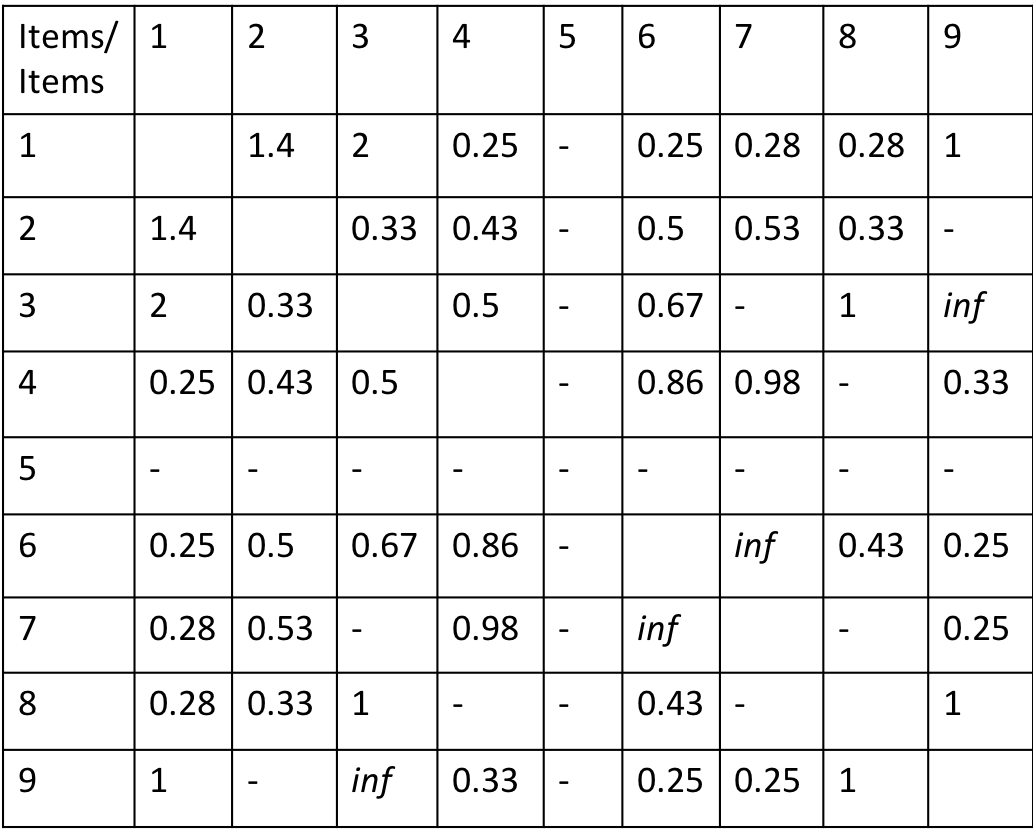
The similarity score — means that these 2 items have never reviewed by any common user and the score inf means that the two items are very similar.
Based on the Item Similarity Table if a user purchases the Item 1, we should recommend items from the Row 1 in the table above in the decreasing order of similarity score (items: 3,2,7,8,4,6)
For the recommender Customers who bought this item also bought, Amazon uses its own version of Item to Item Collaborative Filtering under the hood. Read this paper to find out more about the algorithm used by Amazon.
Advantages of Memory Based Collaborative Filtering
- The biggest advantage of using Memory Based Collaborative Filtering is that, it can be easily applied cross domain. One doesn’t need to know about the details of item and simply build a system based on the user-rating data.
- It is a simple algorithm to implement that can give you good results.
Limitations of the Memory Based Collaborative Filtering
- Scalability: You need to load the entire data in memory to generate item-item or user-user similarity matrix. Every time a new user is added or a new item is added, you need to reload the entire ratings data to generate the similarity matrix.
- Sparsity: There are millions or products sold online, and a few users out of the millions of users review the products. Thus the user-item rating matrix is very large and sparse. One solution is to decrease this sparsity is to fill the missing ratings of the purchased items by users with the average rating of the product.
- Cold Start Problem: To understand this, let’s revisit the user ratings table (Table 1). In this table we see that Item 5 has never been bought by any user in our database. Now when a new User K purchases this item, we will not be able to generate any kind of recommendations for this user, since out database has no information about either the User or the Item purchased. This is known as a cold start problem.
Evaluation of Recommender System
I have been tasked to build a user based recommender system. I decide to use the inverse of Euclidean distance (Recommender 1) for similarity measure, but my colleague has a different opinion that using Cosine Similarity (Recommender 2) will perform better. To decide which of these two recommender systems will generate better recommendations, I can use any of the following methods.
- If I have a small database of users, I can generate recommendations using both recommender systems and do a quality check of which generates better recommendations. However, in case of large datasets with millions of users and items, this isn’t a scalable technique.
- Offline Evaluation: As the name suggests this method generates metrics in an offline (isolated) mode, without the actual users being involved. To evaluate the system using this technique, you split your user rating data into train and test dataset. Now, you train your different versions of Recommender Systems on train dataset and compare the predictions with the ratings in the test dataset.
- Online Evaluation with A/B testing. This method uses the interaction with the actual users to evaluate the system. I will divide the traffic to my website in 2 groups (equal to number of versions I want to test). Now to evaluate which recommender system is performing better, I can measure and compare either of the following metrics from these 2 groups.
- Number of recommended items clicked
- Number of recommended items purchased
- Number of recommended items rated higher
This article will help you take a first step in understanding the complex Recommendations Systems that have increased sales over time for many e-commerce companies. McKinsey’s report shows that 35% of Amazon’s purchases and 75% of items watched on Netflix are a result of their Recommendation Systems.
If you would like to experiment with recommender systems or build one of your own, here is actual customer review data , that you can use, shared by Kaggle.
Member discussion