7 AI Terms Everyone Must Know in 2020

Just like the PC revolution AI is also going to become an integral part of every profession
54% of employees of large companies would need to up-skill in order to stay employed by 2025 — a 2018 Forbes report claimed. Last year $143K was the average salary for a machine learning engineer in the US.
In 2016 Sunder Pichai, Google’s CEO, wrote in a blog, that “The last 10 years have been about building a world that is mobile-first, turning our phones into remote controls for our lives. But in the next 10 years, we will shift to a world that is AI-first”

The PC revolution was speculated about a lot. A lot of people opposed it when it came but it came swiftly and changed how we work. Every organization and every industry now has computers as an organic part of the workplace. The AI revolution is going to hit faster and harder.
The AI revolution is going to hit faster and harder.
To succeed in the AI-first world, one must know the language it speaks. Here are 10 terms that are used very frequently in the machine learning world.
1) Deep Learning
Deep learning happens due to deep neural networks. A neural network is made up of layers of neurons. A deep neural network is a neural network with 1000s of layers.
Whenever we talk about deep learning it is imperative that we talk about neural networks. Each layer of a neural network learn progressively complex features. The earlier layers learn simple features like lines and edges, the next layer might learn simple shapes like squares, circles, triangles etc. the next layer might learn patterns and textures and so on
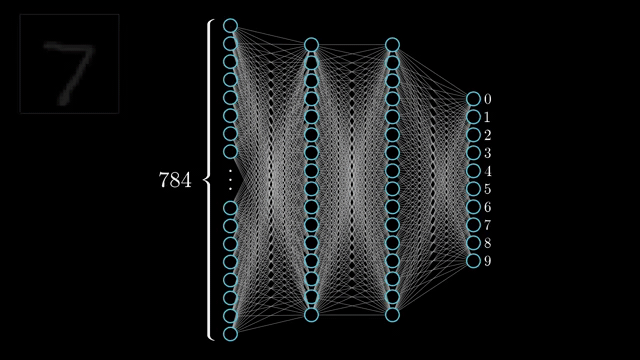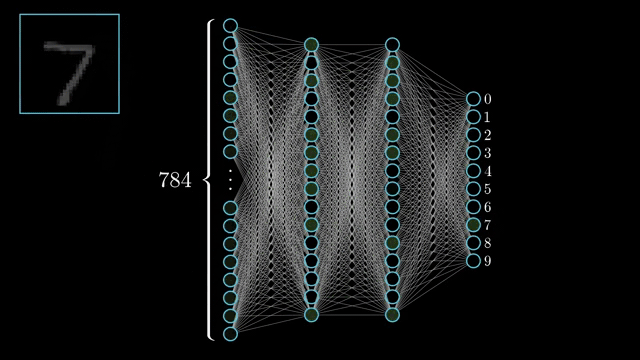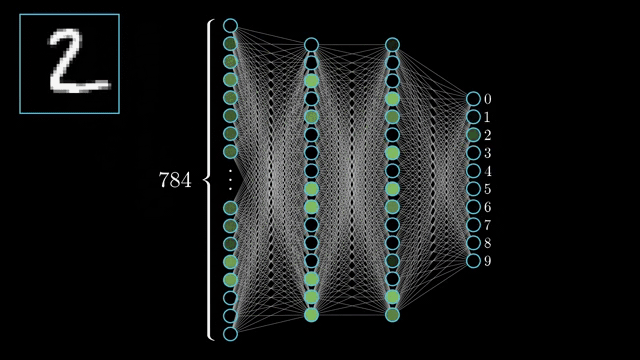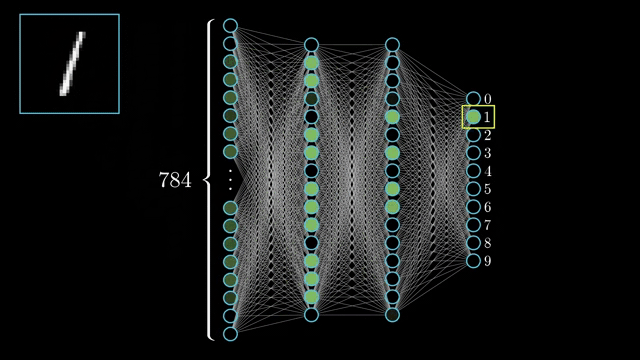
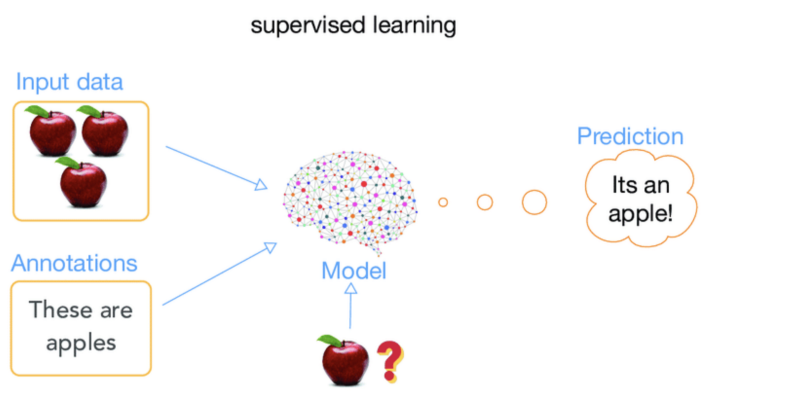
2) Supervised Learning
When data becomes the Yoda for your machine it is known as supervised learning. A huge amount of data is fed to the computer and the machine gets trained by this data. Every data point has a label. Once trained to identify labels the machine can look at a new data point and immediately predict what its label is. The most common algorithms that fall under this category are linear regression, logistic regression and decision trees etc.
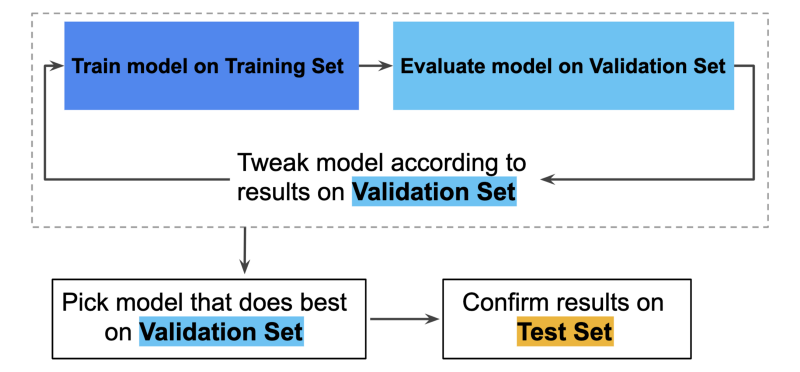
3) Training, Testing and Validation Sets

In any machine learning project we split the data into these 3 parts. The most important commandment of machine learning — One must never touch the test data set. Once the machine is trained we need new data to test it on. We cannot test our machine on a subset of the data it was trained on because the machine has already seen it. The validation set on the other hand is used to tweak the parameters of our algorithm.
The training of neural networks is one of the most resource consuming process. For those who want to delve deeper in this process known as backpropagation do visit this link.
We cannot test our machine on a subset of the data it was trained on because the machine has already seen it
4) CNN — Convolutional Neural Networks
These are the heroes behind the face recognition applications in the world. In the simplest form a CNN deconstructs an image into its most basic elements. For example a face will get broken down into eyes, nose, ears etc. Digit 8 will be broken down into 2 circles, digit 7 into 2 lines one horizontal and one vertical with an angle etc.
5)Recommendation Systems
This is how Amazon and Netflix know what you might like. These systems take in the inputs of your likes, dislikes, preferences, past history, purchases and much more, to generate insights about what you would like in future. Think of them as a computer’s way of reading your mind.

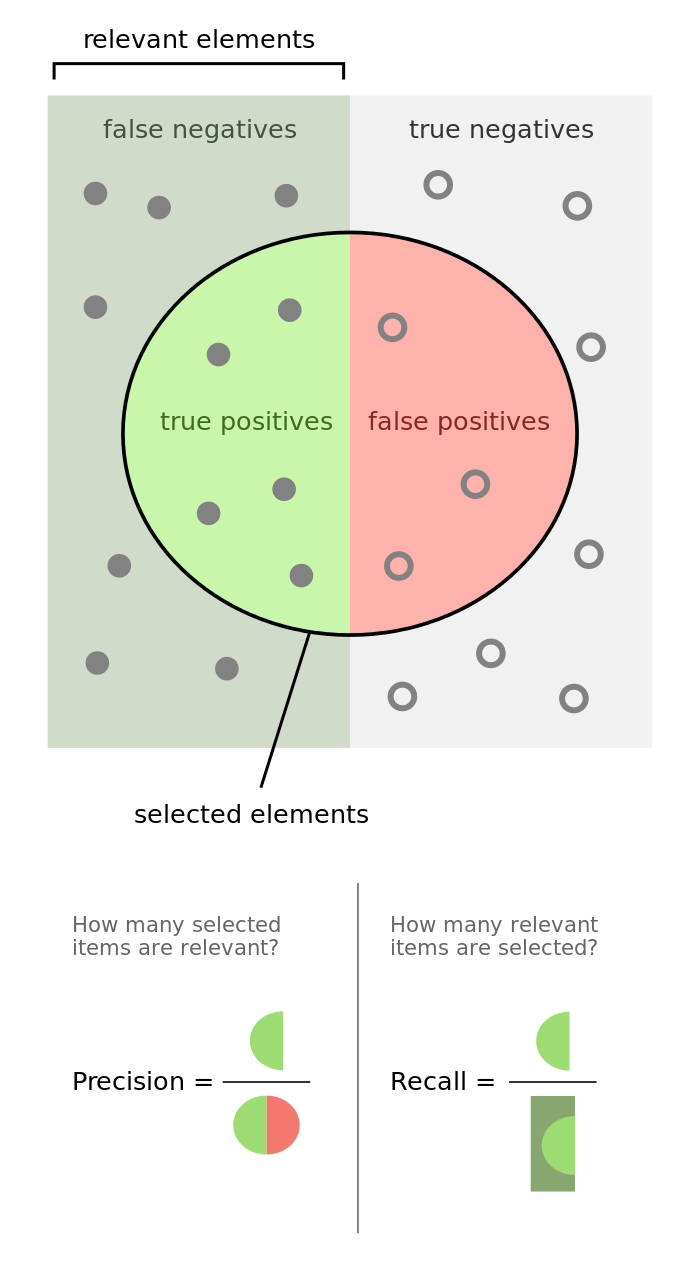
6) Precision and Recall — PR Numbers
The act of using precision and recall numbers is the mathematical way to evaluate how useful is our model with respect to the problem at hand.
For a detailed introduction to PR numbers read this article.
- High Precision & High Recall — The prediction model is highly dependable.
- Low Recall & High Precision — This just means the model is very picky. Such models cannot be used for life critical problems e.g. cancer detection, terrorist identification, accident prevention etc.
- High Recall & Low Precision — This model ends up creating a lot of false alarms. Such models should not be used for cases where false alarms have a huge cost — e.g. flight landing systems.
7) Gradient Descent
Gradient descent is a fast, iterative and an approximate method that aims to find a minimum of a function. It moves iteratively from the starting point in the direction of the steepest descent. In AI this is useful as it helps us find the closest match.
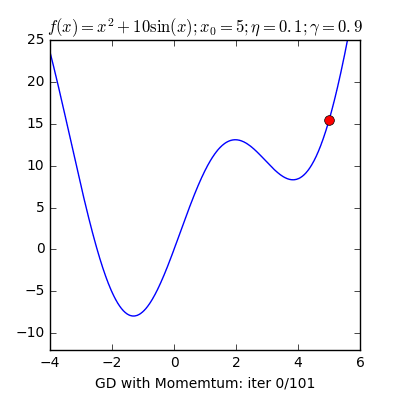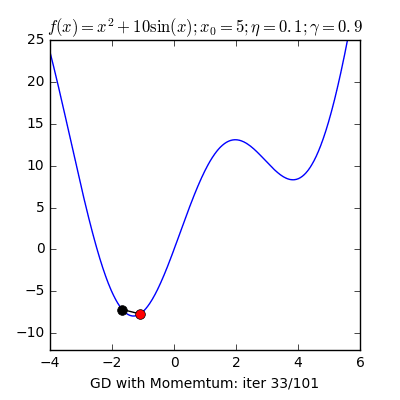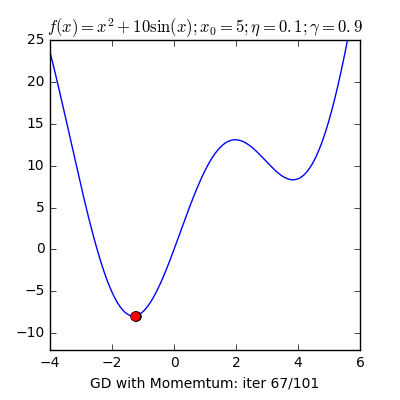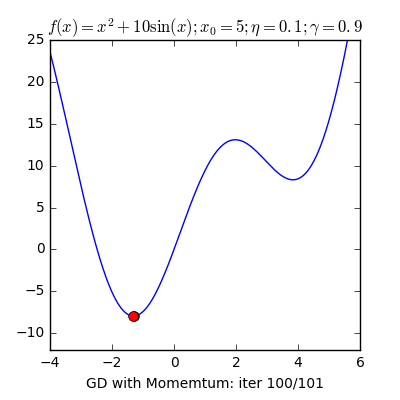
There are numerous other terms that are important. We publish articles exploring the meanings of various such topics and their application. AI Graduate is a community for AI that not only is open source but also looks at the ethical and political aspects of it. We publish an article on such simplified AI concepts every Friday. If you liked this or have some feedback or follow-up questions please comment below.
Thanks for Reading!
Member discussion