Understanding Similarity Measures in ML

There are more than 5 distance functions that are popularly used
The measurement of similarity between 2 objects is computed by mathematical formulae called distance functions.
Almost all machine learning algorithms end up computing distance during the course of their life. kNN uses it during classification step, neural networks use it during training and k-means uses it during the clustering step.
Distance metric is one of the basic computational blocks that are used everywhere in the ML world. Over a period of time different mathematicians have come up with different metrics with their own pros and cons.
Distance tells us how far-off our guess is from the desired answer

The various faces of distance
The similarity measure is the measure of how much alike two data objects are. The similarity is subjective and is highly dependent on the domain and application. For example, two fruits are similar because of color or size or taste. Depending on which dimension you choose (color or size) you will end up concluding different things. On the basis of size apple is similar to orange but on the basis of color apple is similar to cherry.
However, these are mathematical formulae and require mathematical inputs. So eventually we convert our problem into a set of points and then to find the similarity between them we compute the distance between them.
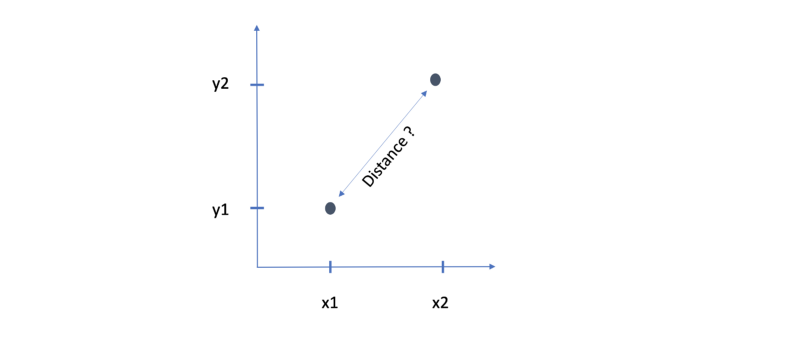
There are many metrics to calculate a distance between 2 points (x1, y1) and (x2, y2) in xy-plane. Some of them are Euclidean distance, or Chebyshev distance or manhattan distance, etc. Each one is different from the others. Let us see how.
Euclidean Distance
When a secondary school teacher asks students to find the distance between two points they are referring to the euclidean distance.
Euclidean distance is the shortest distance between two points in an N dimensional space also known as Euclidean space. N = 2 forms a plane. It is used as a common metric to measure the similarity between two data points and used in various fields such as geometry, data mining, deep learning etc.
It is, also, known as Euclidean norm, Euclidean metric, L2 norm, L2 metric and Pythagorean metric.
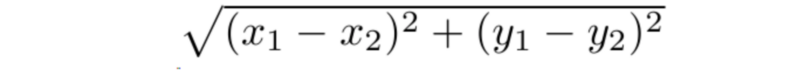
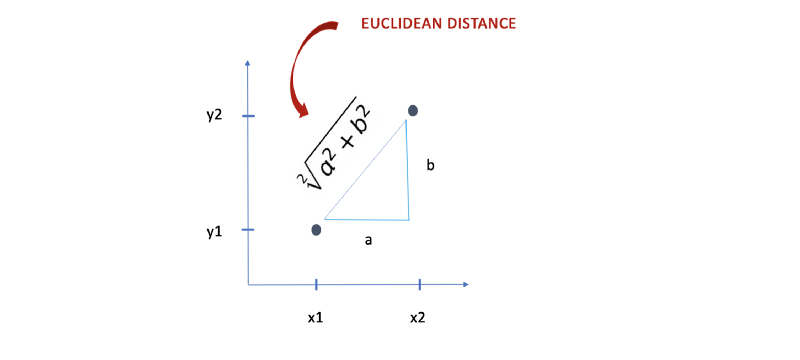
- Cluster Analysis: This metric is commonly used in clustering algorithms such as K-means.
- Data Science: It is used to measure the similarity between two data points.
Manhattan Distance
We use Manhattan Distance if we need to calculate the distance between two data points in a grid like path. Manhattan distance is also known as Taxicab Geometry, City Block Distance, L1 Norm etc. It is used extensively in fields like regression analysis and frequency distribution. It was introduced by Hermann Minkowski.
Because of the grid like path there can be many paths between the two points that are equal to the manhattan distance. The formula for Manhattan Distance is |x2–x1| + |y2-y1| which can be seen as the length of path that needs to be traversed in a grid like fashion. The bars are a mathematical symbol representing the absolute value of the number.
So |-1| = 1 and |1| = 1.
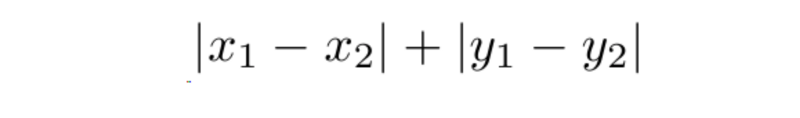
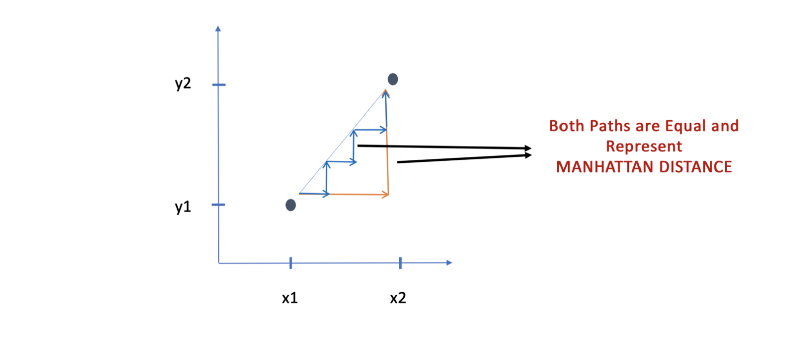
- Compressed sensing: In solving an underdetermined system of linear equations, the regularisation term for the parameter vector is expressed in terms of Manhattan distance.
- In several machine learning applications, it is important to discriminate between elements that are exactly zero and elements that are small but nonzero. In these cases, we turn to a function that grows at the same rate in all locations, but retains mathematical simplicity: the L1 norm.
Chebyshev Distance
Chebyshev distance is the maximum absolute distance in one dimension of two N dimensional points. This is best explained by an example
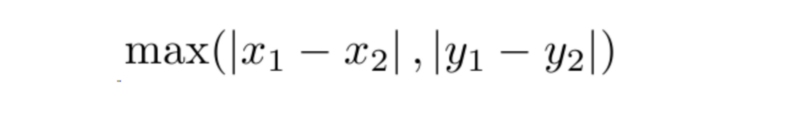
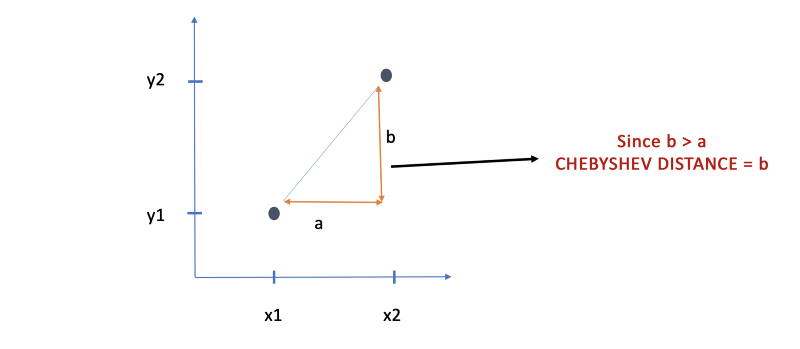
- Chess: The minimum number of moves needed by a king to go from one square on a chessboard to another equals the Chebyshev distance between the centers of the squares
- Warehouse logistics: The Chebyshev distance is sometimes used in warehouse logistics as it effectively measures the time an overhead crane takes to move an object
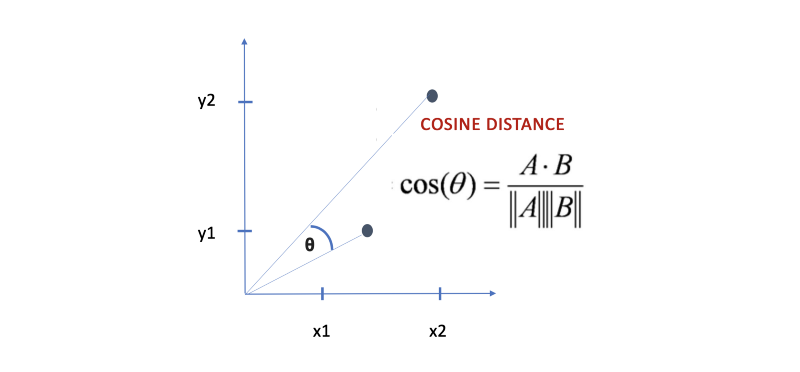
Cosine Distance
Cosine distance is the angle between two lines. These lines are drawn from origin to the points we are interested in. This distance is heavily used in NLP e.g. to measure the degree of angle between two documents. This particular metric is used when the magnitude between vectors does not matter but the orientation.
Irrespective of the distance function it is important to understand when and where to apply each of them. There exist many more functions that are popularly used. We will try to cover them in future articles.
X8 aims to organize and build a community for AI that not only is open source but also looks at the ethical and political aspects of it. More such experiment driven simplified AI concepts will follow. If you liked this or have some feedback or follow-up questions please clap and comment below.
Thanks for Reading!
Member discussion