Use of Cross Validation in Machine Learning

Data is costly but setting aside some data for cross validation is a must. Here’s how and why one must do it!
Data is the currency modern organisations run on. For companies that actively deploy machine learning algorithms data is even more important — for them it is oil.
To understand the need for techniques like cross-validation let us first see all the buckets where data goes.

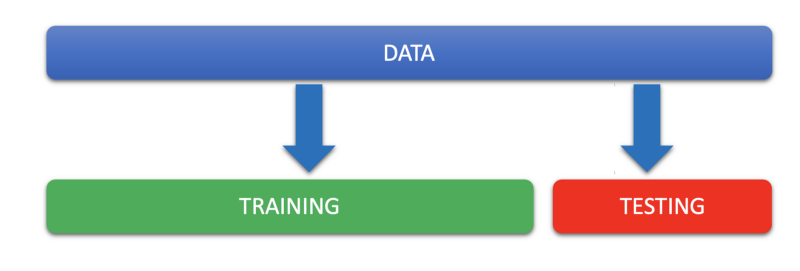
We all understand that data is used to train models on and the more data we have the better are these models trained. But no company can dare release the model they’ve built without testing it first. So one needs to set aside some data for testing. Beyond training and testing most people have not heard the term called validation.
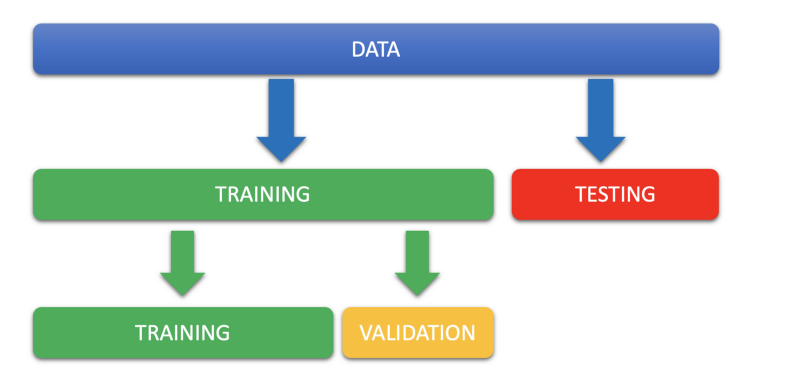
Validation is the process of making sure that the model generalizes well. Generalization is when model is built using one set of data and it performs well on a completely different set of data. Validation set is that other bucket of data on which we improve the generalization error.
The use of validation set
Validation set serves two purposes.
- It is used to fine tune “hyper-paramters” of the machine learning algorithm
- It serves as an intermediary test set.
Basic understanding of hyper-parameters
Every machine learning model has parameters and can additionally have hyper-parameters. Hyper-parameters are those parameters that cannot be directly learned from the regular training process. These parameters express “higher-level” properties of the model such as its complexity or how fast it should learn.
If machine learning model was an AM radio, the knobs for tuning the station would be its parameters but things like angle of antenna, height of antenna, volume knob would be hyperparameters.
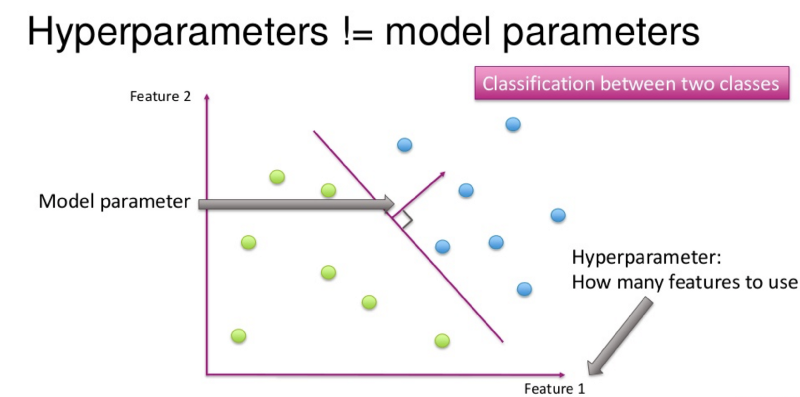
While the objective of the training set is to learn parameters — such as the slope and intercept in the linear regression algorithm, the objective of validation set is to tune the hyper-parameters.
Example of hyper-parameters
If you take sneak peak into the simplified Random Forest article, you’ll remember that there was a step where we had to build a number of decision trees from our dataset. In doing so, we needed to decide the number of trees to build and the number of features to consider when splitting a node. Both of these form the hyper-parameters for Random Forests.
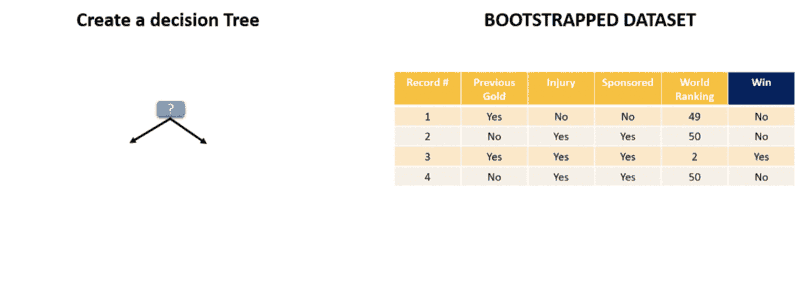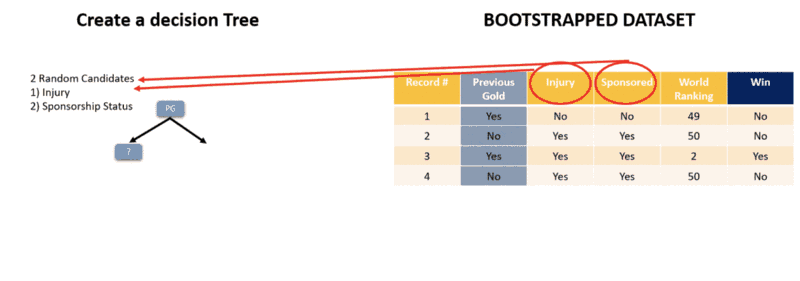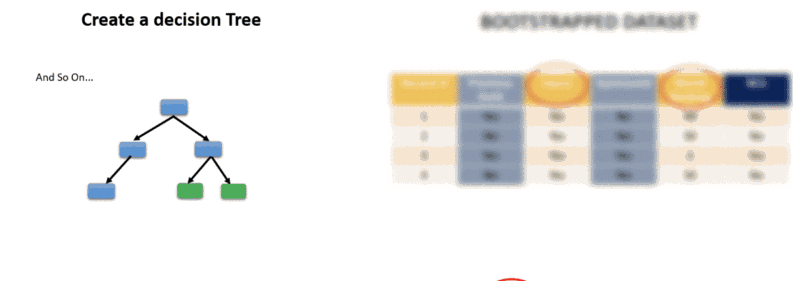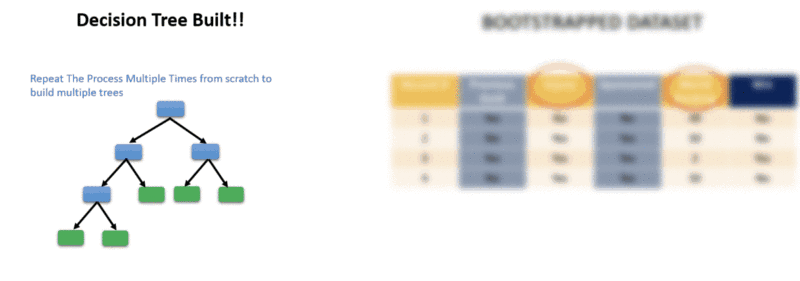
The parameters of a random forest are the variables and thresholds used to split each node learned during training.
Intermediate test set
Validation set also acts as the intermediate testing step for our algorithm. This is especially useful considering that the only commandment of any ML algorithm is
Thou shall never touch the test set
We never even look at the test set while we are still fine tuning our model. This is because test set is the closest we can come to seeing the behaviour of our algorithm in the real world. Before we expose our ML system to the real world the test set sits as the proxy for the real world. If we use any information from the test set during our training phase we might end up biasing the model and lead to an eventual failure during real world deployment.
Logically, then we would carve out a data bucket for our validation set. This is where we would run into a problem.
Validation
Validation is the process of tuning the hyper-parameters by splitting the training set. Without a validation set the data split would look something like this.
Now given that we can’t touch the testing set we need to carve out some data from the training set. This creates a problem. The more training data we have the better is our parameter estimate but the more we keep for validation the better are we able to tune the hyper-parameters.
With this trade-off in mind we have a few approaches available for validation.
Hold-Out Validation
Hold-out validation is when we split the dataset randomly into training and validation set. It makes sense to pick up samples randomly for both the training and validation sets because that ways we are not biasing either of them.
A common split when using the hold-out method is using 80% of data for training and the remaining 20% of the data for validation.
Pros
- Fully-independent data — The data that gets separated from training set becomes a fully independent unit. It is never touched for training purposes and thus we get a neat set for intermediate testing
- In the hold-out validation we perform both the training and validation only once. This is a very computationally cheap operation as compared to what we would do in cross-validation.
Cons
- Doesn’t generalize well— the validation estimate of the error can be highly variable, depending on precisely which observations are included in the training set and which observations are included in the validation set.
A much better albeit computationally more expensive method of performing validation is called K-Fold Cross Validation.
K-Fold Cross Validation
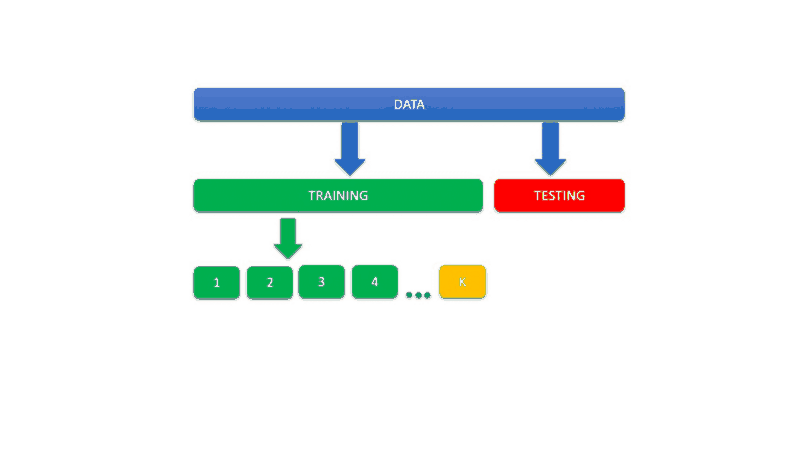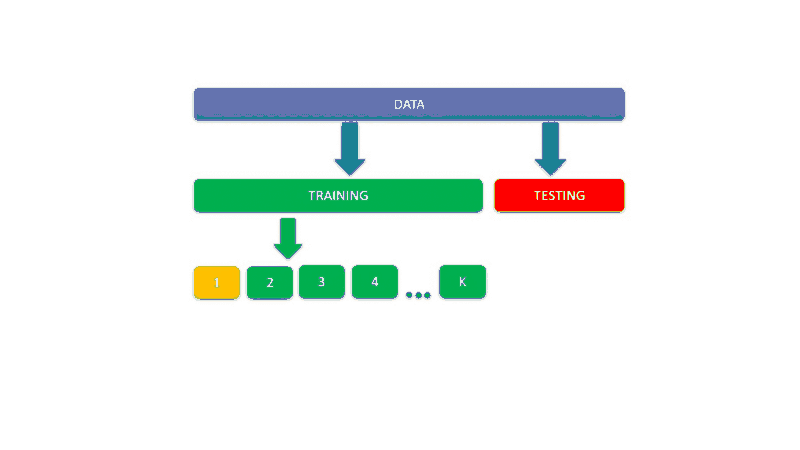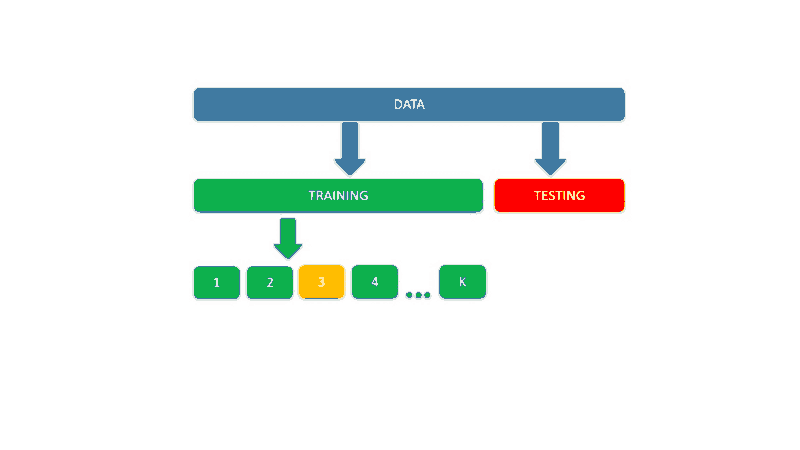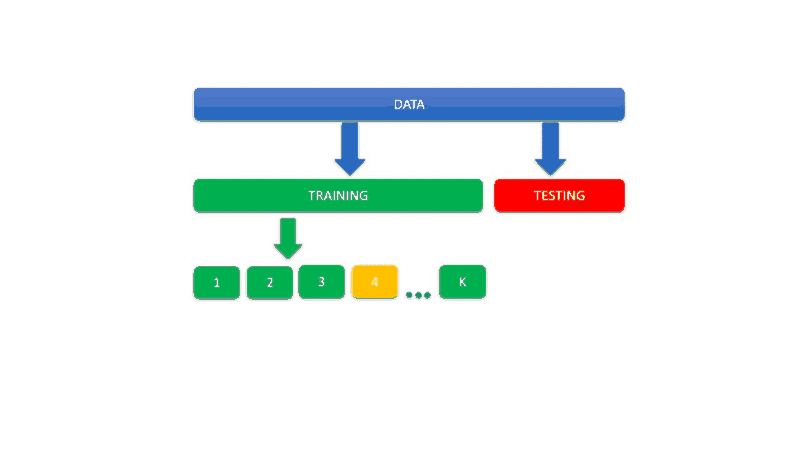
In this the data is split into K buckets called folds.
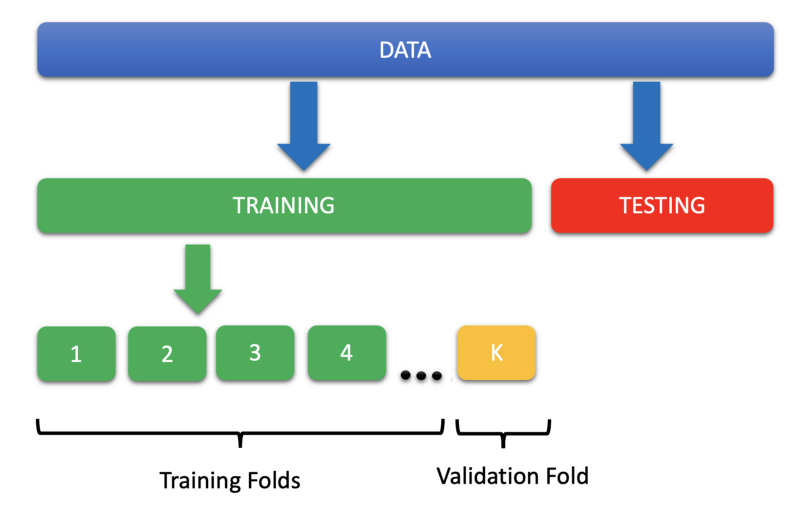
K-fold validation evaluates the data across the entire training set, but it does so by dividing the training set into K folds — or subsections — (where K is a positive integer) and then training the model K times, each time leaving a different fold out of the training data and using it instead as a validation set.
At the end, the performance metric (e.g. accuracy, ROC, etc.) is averaged across all K tests. Once the best parameter combination has been found, the model is retrained on the full data.
Pros
- Free of selection bias — This method goes over the whole of training set and thus there is no selection bias as far as splitting the dataset is concerned
- Generalizes well
- It matters less how the data gets divided
Cons
- High computational cost — The training process is repeated K times which becomes very expensive when training is very costly as in the case of Deep Learning
LOOCV — A Special Case of Cross Validation
“Leave One Out” Cross-Validation is a special case of K-Fold cross-validation where K is equal to the number of total data points. That is the size of bucket is 1 datapoint. This extreme case gives much better results due to very good generalization but is much costlier computationally.
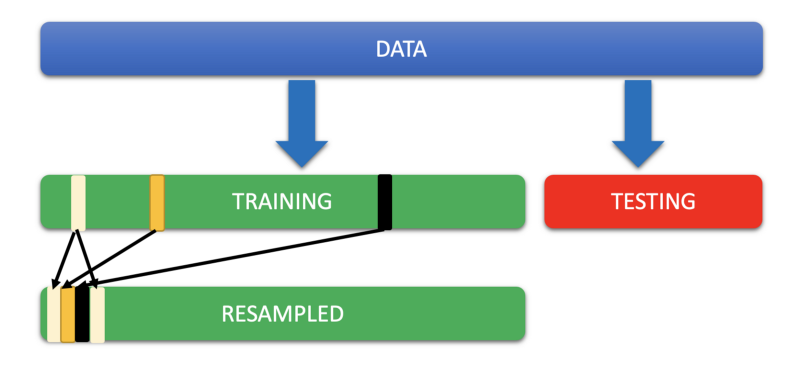
Bootstrap Resampling
In all of the above cases at best we can have a training set that is as big as the original training set. That sounds like an obvious truth. How can you ‘create’ a dataset bigger than the original by sampling?
You can, if you use the bootstrapping technique. Bootstrapping is a statistical technique that falls under the broader heading of resampling.
We perform resampling with replacement i.e. Each datapoint may appear more than once in the resampled dataset.
Bias-Variance Tradeoff
In machine learning two terms are frequently used to describe how well the model fits — bias and variance. Although we need one separate article to explain these two terms, for now it would suffice to know that high bias implies underfitting and high variance implies overfitting.
K-Fold CV tends to be less biased but has fairly large variance. On the other hand, bootstrapping tends to drastically reduce the variance but gives more biased results. So it becomes a matter of choice which of the two we use.
K-fold cross validation is the most commonly used form of validation. Validation in most projects becomes the most crucial step as it prepares your model for the real world. It always helps to have a few techniques under your belt that let you fine-tune your model.
X8 aims to organize and build a community for AI that not only is open source but also looks at the ethical and political aspects of it. More such simplified AI concepts will follow. If you liked this or have some feedback or follow-up questions please comment below.
Thanks for Reading!
Member discussion