Life Cycle of a Data Science Project

The major steps involved in tackling a real-world data science problem

Data science has matured a lot since the term was coined in the 90’s. Experts in the field follow a fixed structure while tackling a data science problem. It is almost an algorithm now to carry out data science projects.
All too often there is a temptation to bypass methodology and jump directly to solving the problem. Doing so, however, hinders our best intentions by not laying a solid foundation to the whole effort. Following the steps however more often than not get us closer to the problem we were trying to solve.
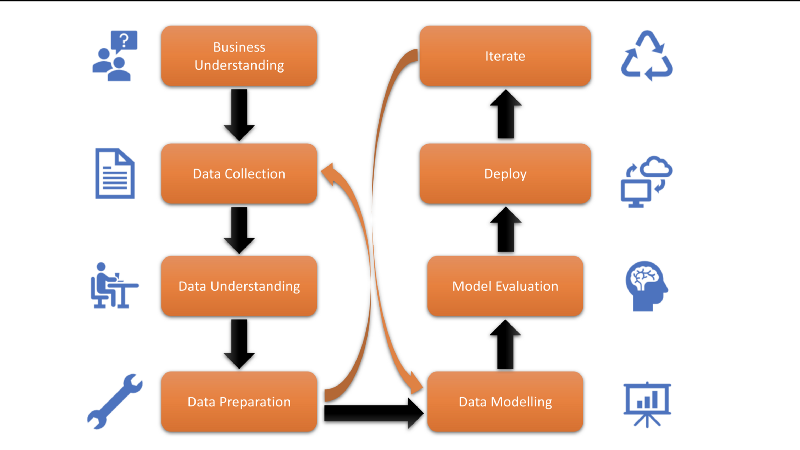
1) Asking the right question a.k.a Business Understanding
Even though access to data and the computing power have both increased tremendously in the last decade the success of an organization still largely depends on the quality of questions they ask of their data set. The amount of data collected and the compute-power allocated is less of a differentiator.
IBM Data Scientist John B. Rollins calls this step as the Business Understanding. e.g. Google in its beginning would’ve asked “What constitutes relevant search results”. As Google grew as a search engine business it started showing ads. Then the right question to ask would’ve been “Which ads are relevant to a user”. A few right questions that other successful businesses have asked in the past of their data science teams
- Amazon — How much compute (EC2) and Storage (S3) space could they lease out during lean periods?
- Uber — What percentage of time do drivers actually drive? How steady is their income?
- Oyo Hotels — What is the average occupancy of mediocre hotels?
- Alibaba — What are the per-square-feet profits of our warehouses?
All these questions are a necessary first step before we can embark on a data science journey. Having asked the correct question we move on to collecting data
2) Data Collection
If asking the right questions is the recipe, then data is your ingredient. Once you have the clarity on business understanding, data collection becomes a matter of breaking the problem down into smaller components.
The data scientist needs to know which ingredients are required, how to source and collect them, and how to prepare the data to meet the desired outcome.
e.g. For Amazon the type of data required would be
- Number of computational servers lying free during lean period
- Number of storage servers lying unused during lean period
- The amount of money being spent to maintain these machines
- The number of startups growing in US at that point
Given the above data Amazon could easily understand how much can they utilise. In reality when Amazon actually answered these questions Bezos was happy to know that this was a very pressing need. This led to the advent of AWS.
How to source and collect
Amazon engineers were tasked to maintain logs of server operations. Market research was conducted to understand how many people would benefit from pay-per-use servers and only then did they proceed ahead.

3) Data Preparation
Now we already have collected some data. In this step we understand more about the data and prepare it for further analysis. The data understanding section of the data science methodology answers the question: Is the data that you collected representative of the problem to be solved?
e.g. let’s say Uber wanted to understand whether people would opt to be drivers for them. For this, let’s say, they collected the following data
- Their current income
- The percentage cut cab companies charge them
- The number of rides they fulfill
- The amount of time they sit idle
- Fuel costs
While 1–4 help them in understanding more about drivers no. 5 doesn’t really explain anything about the drivers. The fuel costs do impact Uber’s overall model but don’t really help them answer their original question.
To understand the data a lot of people look at the data statistics like mean, median etc. People also plot the data and look at its distribution through plots like histogram, spectrum analysis, population distribution etc.
Once we have a better understanding of our data we prepare it for further analysis. Preparation usually involves the following steps.
- Handling missing data
- Correcting invalid values
- Removing duplicates
- Structuring the data to be fed into an algorithm
- Feature engineering
Data preparation is similar to washing veggies to remove the surface chemicals. Data collection, data understanding and data preparation take up to 70% - 90% of the overall project time.
This is also the point where if you feel the data is not proper or enough for you to proceed you go back to data collection step.
Once the data is prepared and cleaned we move on to the core of any data science project — modelling
4) Data Modelling
Modelling is the stage in the data science methodology where the data scientist has the chance to sample the sauce and determine if it’s bang on or in need of more seasoning
Modelling is used to find patterns or behaviours in data. These patterns either help us in one of two ways — 1) descriptive modelling e.g. recommender systems that is if a person liked the movie Matrix they would also like the movie Inception or 2) predictive modelling which involves getting a prediction on future trends e.g. linear regression where we might want to predict stock exchange values
In the machine learning world modelling is divided into 3 distinct stages — training, validation and testing. These stages change if the mode of learning is unsupervised.
In any case once we have modelled the data we can derive insights from it. This is the stage where we can finally start evaluating our complete data science system.
The end of modelling is characterized by model evaluation where you measure
- Accuracy — How well the model performs i.e. does it describe the data accurately.
- Relevance — Does it answer the original question that you set out to answer
5) Deploy and iterate
Finally all data science projects must be deployed in the real world. The deployment could be through an Android or an iOS app just like cred or it could be through a WebApp like moneycontrol.com or it could be as an enterprise software like IBM Watson
Whatever the shape or form in which your data model is deployed it must be exposed to the real world. Once real humans use it, you are bound to get feedback. Capturing this feedback translates directly to life and death for any project. The more accurately you capture the feedback, more effective will be the changes that you make to your model and more accurate will your final results be. At this point typical organizations document this flow and hire engineers to keep iterating the whole flow.
A data science project is an iterative process. You keep on repeating the various steps until you are able to fine tune the methodology to your specific case. Consequently, you will have most of the above steps going on parallely. Python and R are the most used languages for data science. Data science is a rabbit hole. Have fun going deeper!
Member discussion