Demystifying Time Series Machine Learning

In almost a gold-rush way the Tech Giants are in a frenzy to process time series data.
Popularity
At the beginning of 2019 Amazon launched a complete tool to analyze just the Time-Series data. Google made a similar move in September 2018.
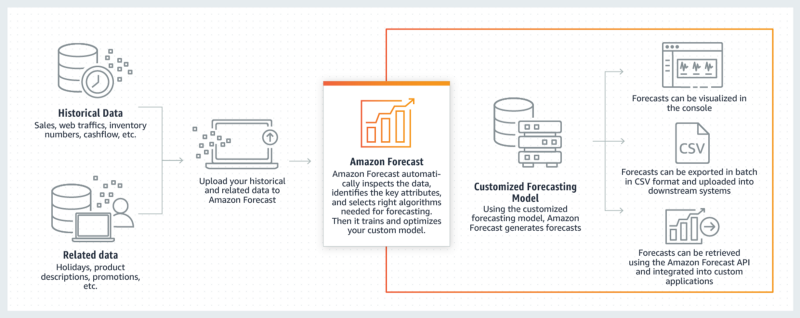
In February 2018 InfluxData, a startup that started building an open source toolkit for time-series processing in 2014, announced its series C funding round of $35M. Today they have more than 120K customers using their open source pipeline and 400 enterprise customers. Why has time series become so important suddenly? The answer lies in how the current state of technology produces data.
Time Series Data
By definition, any data that has ‘time’ as one of its variables is time-series data. Additionally, you always receive the data ordered in time.
Time series data is ordered by time
The data is received in only one direction i.e. if time is plotted on X-axis you only receive the data in the right direction. The past is fixed. No new data will modify the old values.
In today’s world of IoT and sensors, we are getting huge amounts of real-time data. Cisco estimates that by the end of 2019, the IoT will generate more than 500 zettabytes per year in data. A zettabyte equals (1,000,000,000,000,000,000,000 Bytes).
All this real-time data has immense opportunities. It is the new age gold mine. It is this very data that enables Google Maps to show traffic conditions, that enables live flight, train and cab tracking, pollution and weather tracking etc.
Real-time data processing has immense advantages in every field from biology to manufacturing e.g. predicting heart attacks before they occur or stock market changes or even machine breakdown before it occurs to help reduce downtime and hence losses.

Examples
All the pictures below have time on their x-axis.
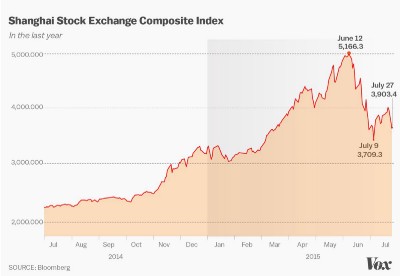
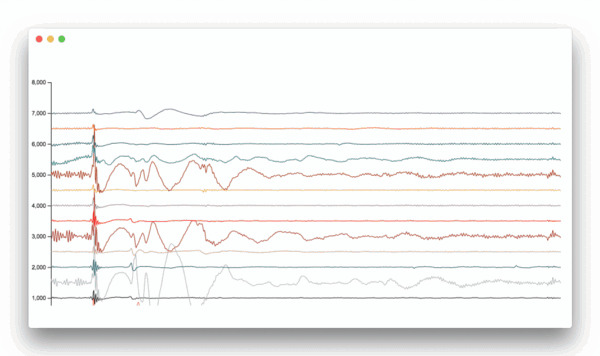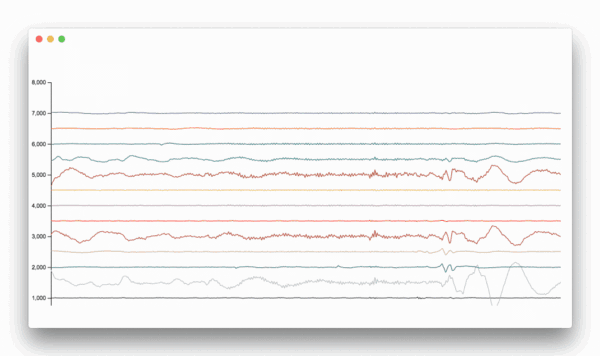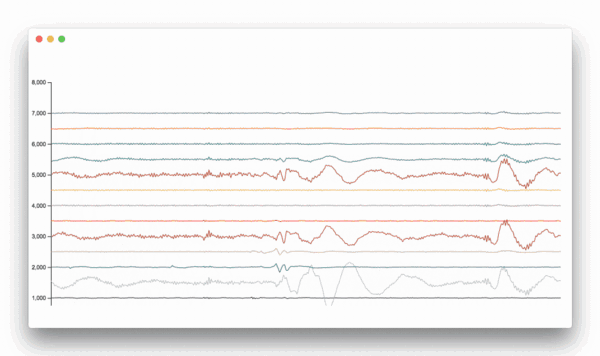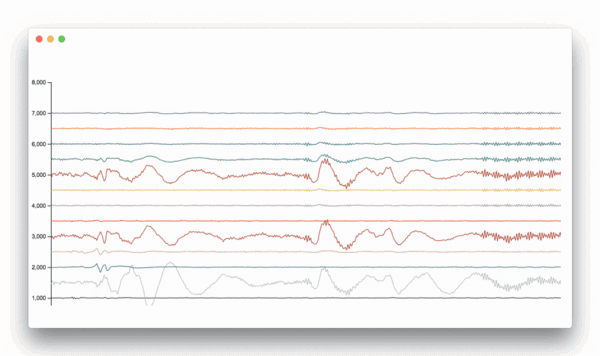
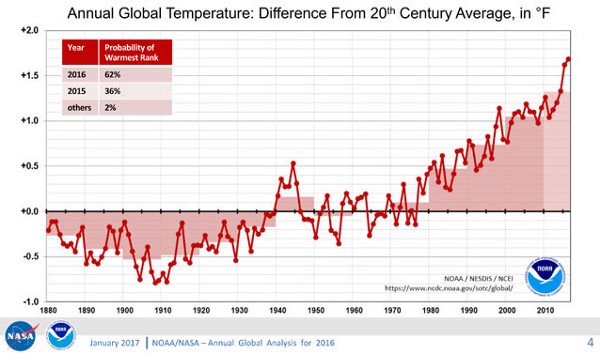
Okay, we are surrounded by time-series data by why is it important to us Machine Learning people?
Time series is a life saver when it comes to machine learning
Any data ordered in time has very interesting features that can be extracted from it. Let’s say the heartbeat of a person was fine 2 hours ago but is erratic now. This information could be highly useful in preventing stroke and heart attacks. Similar information can help manage natural disasters, terrorist attacks, financial crashes and machine breakdown.
Machine learning algorithms love such kinds of data. Time series data can inform machine learning in myriad ways.
- Helps assign labels to the data by looking at high and low activity data. e.g. normal and erratic heartbeat
- Extract statistical features of the data e.g. the rising or falling trends and the speed of rising.
- In the absence of any other clear features, it can help understand the mechanism for the generation of the series itself
- Forecast. The data can help us forecast what is going to happen in the future. This has immensely useful applications in healthcare, predicting earthquakes, sales, etc.

Machine Learning engineers must keep in mind these 10 commandments
“Time-series data tends to be big, so performance and scalability are crucial. The key requirements for working with time-series data are the abilities to analyze and aggregate the data very, very quickly.”
- Thou shall not depend on a single variable — Time series data is very complex. Quite often, a single variable is not enough to determine a system. Go for multivariate time series analysis
- No 2 variables are alike — Each variable can have a different sampling rate. The temperature may be sampled every hour and humidity might be sampled every day.
- Thou shall be patient — A single snapshot of time may not be enough to deduce information about all the states in the signal. Analysis of long periods of data is required. Thus voluminous time history traces of data need to be digested by the algorithms.
- Know thy features — Manual selection of features like mean, moving average, higher order derivatives is infeasible and not very useful in most cases. ARIMA, RNNs and SAX, etc. are useful for feature extraction and are regularly used but nowadays companies like Google and Amazon prefer unsupervised extraction of features
- The change (transform) lies within — Often the above-mentioned feature extraction methods cannot be applied on the raw signal directly. Transforms are needed — spectral analysis, resampling, window optimization, etc.
- Variety is the spice of life — Combination of supervised + unsupervised labeling.It is not always possible to have neatly labeled data. So it becomes necessary to use unsupervised labeling.
- Manage thy data — The need to process signals real-time poses storage challenges. Some amount of memory needs to be reserved to buffer the history of signals to feed into the model. With multiple signals being captured at varying sampling rates synchronization becomes a key issue.
- Beauty lies in the visualizer — Finally, all analysis is useless if there isn’t a way to visualize the insights drawn from the Machine Learning infrastructure. Actionable insights must be provided to organizations to utilize the live time-series data.
Where to get started?
- A good place to get started is a book that handles all the statistical aspects of it and uses the language R.

- There are many tutorials on the internet for performing various machine learning algorithms on TS data.
Time Series Forecasting is a well studied but still growing field. It is poised to overhaul the whole of IoT world and in turn, shape the very reality in which we live.
Member discussion