Machine Learning Algorithms for Every Occasion

Make an informed decision about your choice of algorithm
A machine learning algorithm is a method that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Algorithms like linear regression, deep learning, convolutional neural networks and recommendation systems are widely being used and explained.
It is easy to get lost in this ocean of information. Understanding which algorithm would suit any given situation becomes a winning quality. Generally this role is played by a product manager. Regardless of who calls the shots, it is important to understand that different situations demand different algorithms.
The guiding principles
Your choice of algorithm depends primarily on 3 factors.
- Quality of input data
- Type of output needed
- Business constraints
1) Quality of input data
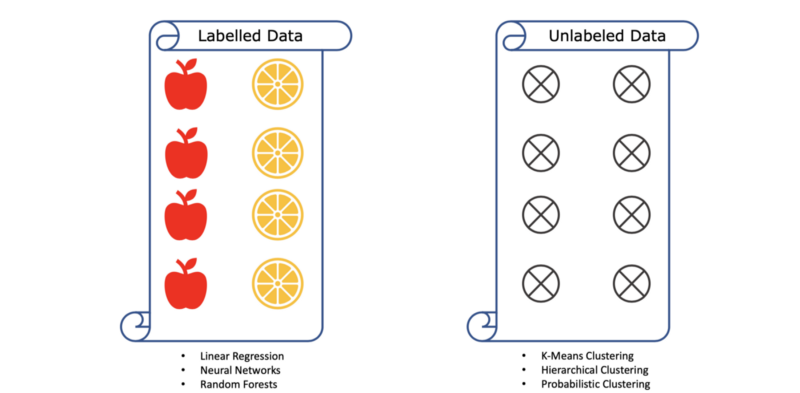
Depending on what all information input data contains one can choose the algorithm. Even the simple concept of whether the data is labelled or not affects the choice of algorithm hugely. Supervised algorithms are best suited for well-labelled data. Algorithms like linear regression, logistic regression, neural networks, random forests etc. are all examples of supervised algorithms.
On the other hand if your data has no labels or has sparse labels then one can use unsupervised learning algorithms like clustering.
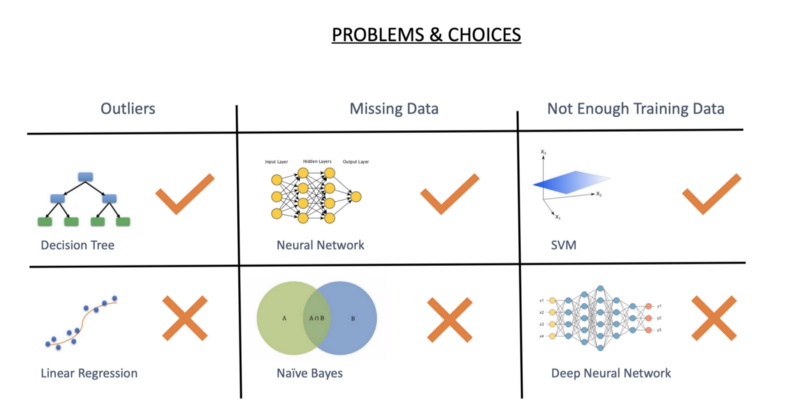
No dataset is perfect. Real world data collection is rife with problems like—missing data, noisy data, less data than what the algorithm needs.

So for example there are a lot of outliers in your data then linear regression will perform extremely poorly but decision trees would be a fairly stable solution.
Similarly missing data affects Naive Bayes much more than it affects Neural Networks. SVM would perform much better than a Deep Neural Network when there is not enough of training data.
2) Type of output needed
If you need your output to predict tomorrow’s stock price then the algorithm would be a time-series model. If, on the other hand, you just need an output of whether an email is spam or not you would use classification. The kind of output you need is directly governed by the business questions you need answered.
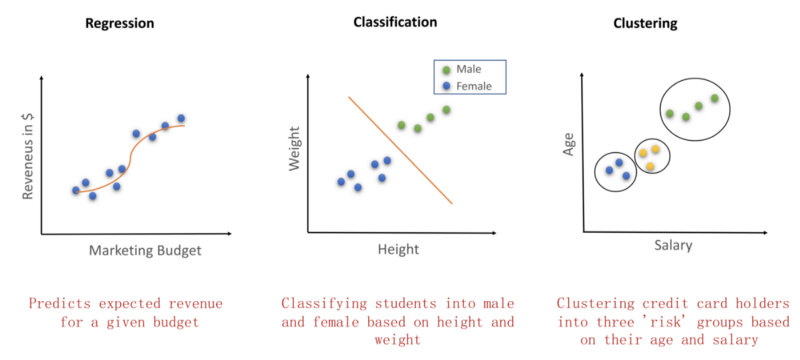
Business question 1 — Let’s say a startup’s marketing team wants to decide the size of marketing budget. They want to base it on the amount of revenues that it would generate. Solving this business question would produce an output of a marketing budget v/s revenue graph. This kind of a problem falls into the domain of linear regression. (leftmost curve)
Business Question 2 — While if the same company wants to separate their users into male and female categories on the basis of just their height and weight, then it becomes a question of classification.
Business Question 3 — If the same company wants to profile their users to understand their credit risk, the algorithm of choice would be unsupervised learning. It is because the data is unlabelled. New credit card users don’t have a risk score or a risk profile on the basis of which they can be categorized. So such companies like to perform clustering of users based on factors like age, salary and location etc. This would then become a clustering problem.
The relation of algorithm with the data
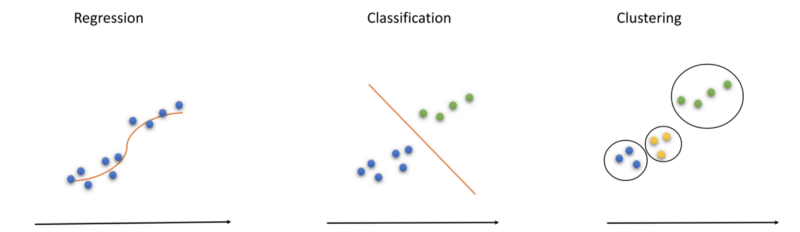
- In regression you fit a line that predicts the trend and any new point on that line can easily tell you what you need.
- Classification on the other hand separates the two classes by a well defined line. Points on either side fall into neat classes.
- Finally, clustering tries to observe all the mini groups (clusters) that can be identified in the whole of dataset. Each cluster can then be treated differently.

Interestingly, regression and classification are supervised algorithms. So e.g. in the trend prediction example we already know a few data points that correspond to the values of (marketing budget, revenue). Since we already know a few pairs before hand we can start predicting revenue for new values of marketing budget.
Similarly, we already know a few males and females in the user segmentation problem. We have their weight and height data. Based on that we draw a line that separates them. Any new person with a given weight and height will fall on either side of the line and be immediately classified.
The 3rd problem however is slightly different. It falls into the unsupervised learning case because we do not have the credit histories of new users. So based on just their age and salary we try to form three clusters and observe their behaviours. Some of these clusters will become high-risk individuals and some low-risk. Based on that a company can choose to offer credit cards.
3) Business constraints
Finally, business constraints guide the choice of algorithm. Business constraints appear in the form of costs involved, the time-to-market, promised speeds to the customers and energy effeciencies.
An edge-IoT company like Fitbit or other smart devices would need algorithms that consume less energy (because of battery constraints) and have a good enough accuracy. They don’t need 99% accuracies. They would thus go for linear regression algorithm or nearest neighbour or SVMs.

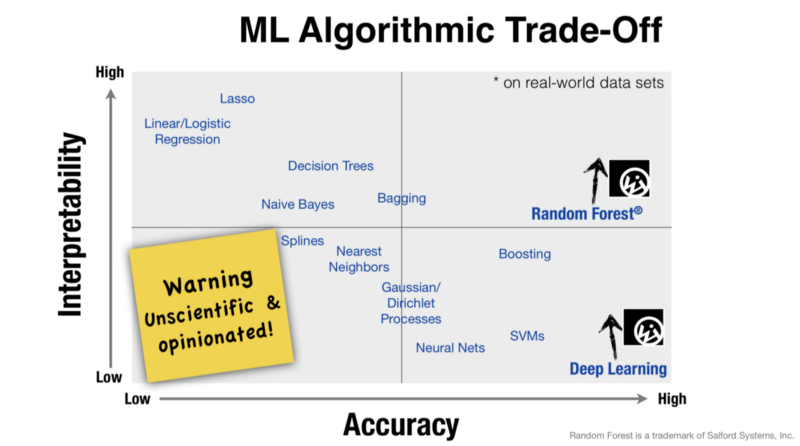
But a company like Tesla that needs self-driving cars doesn’t care much about energy efficiency. It has a lot of stored energy. It does care about accuracy a lot so it uses deep learning.
Similarly a machine learning research team at Stanford would be more interested in interpretability of their models much more than accuracy. Hence teams use decision trees and Naive Bayes.
Computational complexity also matters as it affects the cost and hence choice of hardware. A startup has less money as compared to giants like google so a startup would deploy decision tree algorithm whereas Google would go for a random forest consisting of 1000s of decision trees.
It is a very handy skill to know which algorithm to use. Amongst the plethora of algorithms out there, finding the right one is a must.
Having no choice is bad, having too many is worse!
Member discussion