Build Your First Chatbot in Python

Quickly building a chatbot from scratch is extremely easy in Python
Building a chatbot is a great way to ensure that your customers or visitors get a good experience any time they visit your page. We saw the theoretical components of a chatbot in the article mentioned below.
 Rishi Sidhu
Rishi SidhuLet us now see how to write it in code. We will use python for this.
The Library — NLTK
We will use the NLTK python library to do most of our tasks. Our dataset, machine learning algorithm and preprocessing steps all will come from NLTK. In fact we will download these packages in the beginning of our code.
#NLTK Downloads (Need to do only once)
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('wordnet')
nltk.download('nps_chat')The Natural Language Toolkit (NLTK), is a collection of libraries and programs for natural language processing (NLP) in the Python programming language. It was developed by Steven Bird and Edward Loper in the Department of Computer and Information Science at the University of Pennsylvania.

With NLTK we can do things like
- Splitting sentences from paragraphs,
- Splitting up words
- Recognizing the part of speech of those words,
- Recognizing the type of statement e.g. whether it is a question or an emotion
Tokenisation, stemming, lemmatisation, are some of the things we will do while creating our bot. These technical terms are explained in this article.
The Process
These steps will comprise the making of a chatbot
- Training — We will train a model to detect questions
- Question Bank — Use a pre-recorded question-answer file to build a knowledge-base of questions
- Preprocessing and response fetching — We will pre-process user inputs e.g. stemming, lemmatisation, capitalisation and display bot’s answers to those questions
The complete code gist is here.
This is how the final chatbot will look like
1. Training a model
#Training the classifier
#Fetch the chat corpus
chats = nltk.corpus.nps_chat.xml_posts()[:10000]
#Extract features from chat
featuresets = [(fetch_features(chat.text), chat.get('class')) for chat in chats]
#Split them into test ad train sets 90-10 split
size = int(len(featuresets) * 0.1)train_set, test_set = featuresets[size:], featuresets[:size]
#Use the classifier of choice
classifier = nltk.MaxentClassifier.train(train_set)
#classifier = nltk.NaiveBayesClassifier.train(train_set) #If you need to test Naive Bayes as well
#Print the final accuracy
print(nltk.classify.accuracy(classifier, test_set))Dataset — NPS Chats
We will train our bot to understand questions by training it on a database of chats.
NLTK comes bundled with huge ‘text datasets’. Any real world application in Natural Language Processing typically utilises these large bodies of linguistic data, or corpora, either for training or testing the models. We will be using the corpus called NPS Chats.
The NPS Chat Corpus has approximately 500,000 posts gathered from various online chat services. The posts have been privacy masked by removing all usernames and by removing personally identifiable information through manual inspection..
This is how the first few posts of the dataset look.
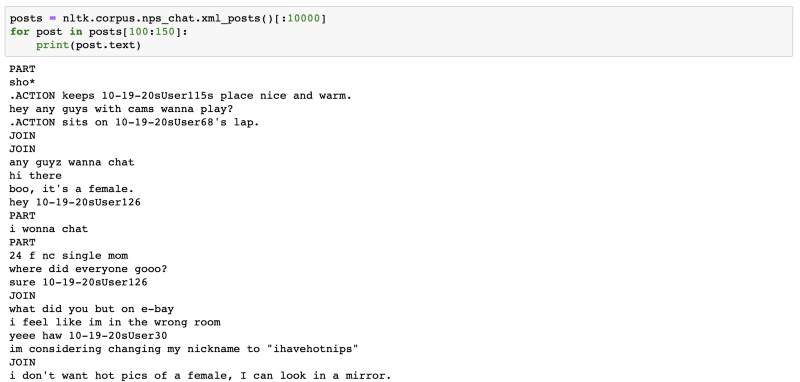
Each file is a recording from age-specific chat rooms for a short period on a particular day. Sentences are classified into one of the following categories — Accept, Bye, Clarify, Continuer, Emotion, Emphasis, Greet, No Answer, Other, Reject, Statement, System, Wh-Question, Yes Answer, Yes/No Question.
The classifier — MaxEnt
The classifier we use to train on the NPS Chat database is called the maxent classifier. In my experiments this classifier did a better job of predicting questions than the Naive Bayes classifier(the more popularly used classifier).
What is the MaxEnt Classifier?
The maximum entropy classifier is a classifier that makes no assumptions on the interdependence of features. It can be used to solve a large variety of text classification problems such as language detection, topic classification, sentiment analysis etc.

When to use the MaxEnt Text Classifier?
Due to the minimum assumptions that the maximum entropy classifier makes, it is commonly used in Text Classification problems where the features are words which obviously are not independent. We found Max Entropy takes more time to train than Naive Bayes.
2. Building a question bank
#Reading a scraped faq text
ques_bank = open('canada_faq.txt','r',errors = 'ignore')
qb_text = ques_bank.read()
qb_text = qb_text.lower()
sent_tokens = nltk.sent_tokenize(qb_text)# converts to list of sentences
word_tokens = nltk.word_tokenize(qb_text)# converts to list of words
#Data structures to store questions and answers
qa_dict = {} #The Dictionary to store questions and corresponding answers
q_list = [] #List of all questions
s_count = 0 #Sentence counter
#Extract questions and answers
#Answer is all the content between 2 questions [assumption]
while s_count < len(sent_tokens):
result = classifier.classify(fetch_features(sent_tokens[s_count]))
if("question" in result.lower()):
next_question_id = s_count+1
next_question = classifier.classify(fetch_features(sent_tokens[next_question_id]))
while(not("question" in next_question.lower()) and next_question_id < len(sent_tokens)-1):
next_question_id+=1
next_question = classifier.classify(fetch_features(sent_tokens[next_question_id]))
q_list.append(sent_tokens[s_count])
end = next_question_id
if(next_question_id-s_count > 5):
end = s_count+5
qa_dict.update({len(q_list)-1:[s_count+1,end]})
s_count = next_question_id
else:
s_count+=1Broadly speaking there are 2 types of bots.
- Retrieval based bots — which answer based on the retrieval of pre-stored and processed information
- Generative bots — which are more intelligent and use generative models like LSTM to respond rather than depending on pre-stored information.
The bot that we are making in this tutorial is of the former type i.e. retrieval based. It is less intelligent and more purpose driven. For example, it will be a bad conversational bot for a psychology helpline but a very good customer service bot for a bank helpline.
To make such a bot one needs to feed it a dataset which has questions and answers in it. In my case I scraped the FAQ pages of various sites like Amazon EC2, The New Yorker FAQ, Canada Immigration website, Wells Fargo website, interview prep website etc. Once you have this data you preprocess it (stemming etc.) and have your MaxEnt model detect and store the questions and their corresponding answers. In the next step we will take a user’s input and match to one of the stored questions.

3. Preprocessing and response fetching
#Lemmatization
def lemmatise(tokens):
return [lem.lemmatize(token) for token in tokens]
remove_punctuation = dict((ord(punct), None) for punct in string.punctuation)
#Tokenization
def tokenise(text):
return lemmatise(nltk.word_tokenize(text.lower().translate(remove_punctuation)))
#TF-IDF Question Matching And Response Fetching
def match(user_response):
resp =''
q_list.append(user_response)
TfidfVec = TfidfVectorizer(tokenizer=tokenise, stop_words='english')
tfidf = TfidfVec.fit_transform(q_list)
vals = cosine_similarity(tfidf[-1], tfidf)
idx = vals.argsort()[0][-2]
flat = vals.flatten()
flat.sort()
req_tfidf = flat[-2]
if(req_tfidf==0):
resp = resp+"Sorry! I don't know the answer to this. Would you like to try again. Type Ciao to exit"
return resp
else:
resp_ids = qa_dict[idx]
resp_str = ''
s_id = resp_ids[0]
end = resp_ids[1]
while s_id<end :
resp_str = resp_str + " " + sent_tokens[s_id]
s_id+=1
resp = resp+resp_str
return respThis step involves taking in user input, process it (lemmatising and stemming) and matches it to the stored questions. But how do you match words with each other?
Python’s scikit library provides a function called TF-IDF Vectorizer which basically converts words into vectors of numbers. These numbers then can easily be matched.
The details of what TF-IDF is not relevant in this article but I will cover it in detail in the next one. An article by Radhika Bansal does touch upon this topic if you do want to read. For now assume that it is the tool that matches a user entered question with a pre-stored question e.g. this tool will count the following 2 questions as the same
- User: “Apply for travel visa?”
- Stored: “How do you apply for Canada’s travel visa?”
Once a question is found the bot responds with the corresponding answer which is also pre-stored along with the question.
Although the bot is not a very intelligent one it still acts as a pretty good FAQ responder. I encourage you to scrape/copy the FAQ page contents of any website, write it in a .txt file and try to build your own bot. Just replace the FILENAME variable.
The complete code gist is pasted below.
AI graduate aims to organize and build a community for AI that not only is open source but also looks at the ethical and political aspects of it. More such experiment driven simplified AI concepts will follow. If you liked this or have some feedback or follow-up questions please comment below
Member discussion